Chapter1
Introduction
운영체제(OS)란?
컴퓨터의 하드웨어를 관리하는 소프트웨어이다. OS는 응용프로그램의 기반을 제공하고, 컴퓨터 사용자와 컴퓨터 하드웨어의 매개역할을 한다..
현대 컴퓨터 환경의 OS의 역할을 탐구하기 위해, 컴퓨터 하드웨어(CPU, 메모리, I/O device, 저장장치 등)의 조직, 구성을 이해하는 것이 가장 중요하다. OS의 근본적인 역할은 이러한 자원들을 프로그램에 할당하는 것이다.
OS의 목표
● 사용자 프로그램을 실행하고 사용자 문제들을 쉽게 풀 수 있게 해준다.
● 컴퓨터 시스템을 사용하기 편리하도록 만들어준다.
● 컴퓨터 하드웨어를 효율적인 방법으로 사용한다.
이 장에서는, 컴퓨터 시스템의 주요 구성요소에 대한 전반적인 개요, OS가 제공하는 기능들에 대해 살펴본다.
Chapter Objectives
● 컴퓨터 시스템의 일반적인 구성과 interrupt의 역할을 설명
● 현대의 multiprocessor computer system의 구성요소에 대해 설명
● user mode에서 kernel mode로의 전환에 대해 설명
● OS가 다양한 컴퓨팅 환경에서 어떻게 사용되는지 논의
● 오픈소스 OS의 예
1.1 What Operation Systems Do
컴퓨터 시스템은 크게 4가지 구성요소로 나뉜다
● 하드웨어 : CPU, 메모리, I/O devices 등이 있고, 기본적인 computing resources 제공한다.
● OS : 하드웨어를 제어하고, 다양한 사용자를 위해 다양한 응용프로그램 간의 사용을 조정한다.
● 응용프로그램 : 워드 프로세서, 스프레드시트, 컴파일러, 웹 브라우저 등이 있고, 사용자의 컴퓨팅 문제에 대해 이러한 자원들이 사용되는지에 대해 정의한다.
● 사용자
1.1.1 User View
많은 사용자들은 랩탑 또는 모니터, 키보드, 마우스로 구성된 PC와 앉아있다. 이러한 시스템은 한 사용자를 위해 자원들을 독점하도록 디자인 되어있다. 목표는 작업을 극대화 하는 것이다. 이러한 경우 OS는 어느정도의 성능, 보안에 주의를 기울이지만, 자원 활용에는 신경을 쓰지 않고 사용의 용이를 위해 디자인된다.
1.1.2 System View
컴퓨터의 관점에서, OS는 하드웨어와 밀접하게 관련된 프로그램이다. 이러한 관점에서, OS는 자원할당자(resource allocator)로 볼 수 있다. 문제를 풀기 위해 요구돼지는 자원들이 있다. (CPU time, memory space, storage space, I/O devices …) OS는 특정 프로그램 그리고 사용자에 어떻게 자원들을 할당해서 컴퓨터 시스템을 효율적으로 작동시킬 수 있을지 결정해야 한다.
약간 다른 관점에서, OS는 다양한 I/O devices 그리고 사용자 프로그램을 통제할 필요에 대해 강조한다. OS는 통제 프로그램(control program)이다. Control program은 오류 및 부적절한 컴퓨터의 사용을 막기위해 사용자 프로그램의 실행을 관리한다.
1.1.3 Defining Operating Systems
어떻게 OS에 대해 정의할 수 있을까? 일반적으로, OS에 대한 적당한 정의가 없다. OS는 usable computing system을 만드는 문제를 풀기위한 합리적인 방법을 제공하기 때문에 존재한다. computer system의 근본적인 목표는 프로그램을 실행하고, 사용자 문제를 쉽게 풀기위함이다. bare hardware(추가적인 소프트웨어는 별도옵션으로 판매하며,운영체제(OS)가 비어있는 하드웨어만 일컬음.) 혼자 쓰는것은 쉽지 않기 때문에, 응용프로그램이 개발되었다. 이러한 프로그램들은 I/O device들을 제어하는 작업을 하고, 자원들을 제어하고 할당하는 기능들을 하나의 소프트웨어에 가져다 놓은것이 OS이다.
더 보편적인 정의로, OS는 컴퓨터에서 항상 작동하는 하나의 프로그램이고, 보통 커널(kernel)이라고 불린다. 커널과 함께, 두가지 다른 프로그램이 있다. OS와 연관되어 있지만, 커널의 일부가 될 필요가 없는 시스템 프로그램, 그리고 시스템의 작업과 관련되지 않은 모든 프로그램을 포함하는 응용프로그램(application program)
1.2 Computer System Organization
현대의 범용 컴퓨터 시스템은 하나 이상의 CPU들과 여러개의 device controller들과 bus를 통해서 연결돼있다. bus는 구성요소와 공유 메모리 사이에 접근을 하게 해준다. 각 device coontroller은 특정 타입의 기계(disk drive, audio device, graphics display)를 담당한다. controller에 따라서, 하나 이상의 기계가 연결될 수 있다. (예 : 하나의 시스템 USB포트는 USB허브에 연결될 수 있다.) device controller는 local buffer storage와 special purpose register을 유지한다. device controller은 데이터를 제어하는 주변장치와 local buffer storage 사이에 데이터를 이동시키는 역할이다.
전형적으로, OS는 각 device controller에 대한 device driver을 가지고 있다. 이 device driver은 device controller을 이해하고, OS의 나머지 부분에 장치에 대한 균일한 인터페이스를 제공한다. CPU와 device controller은 병렬로 실행되고, 메모리 사이클에 대해 경쟁한다.
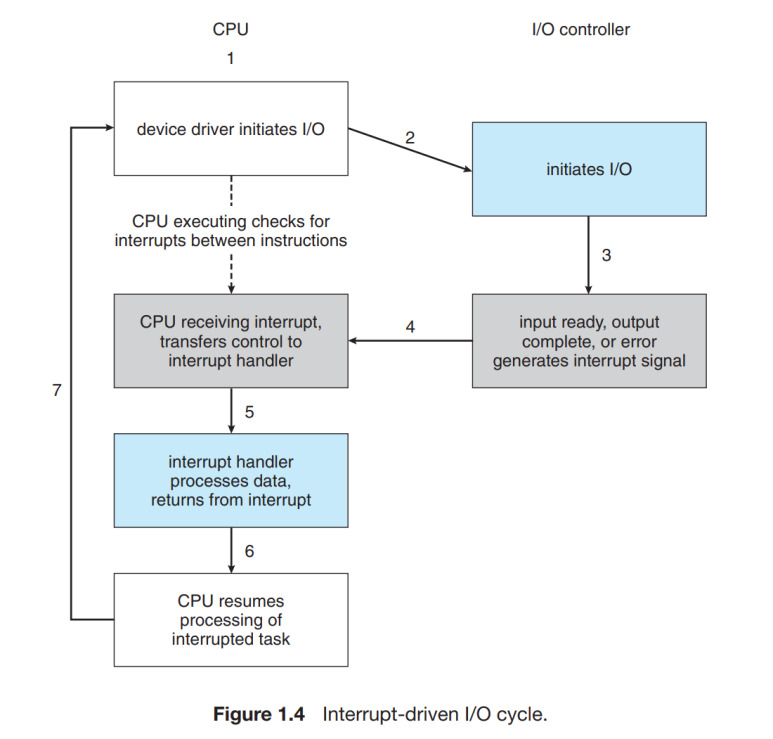
1.2.1 Interrupts
I/O를 담당하는 프로그램을 생각해보자. I/O 작업을 시작하기 위해,
● device driver은 device controller의 적당한 레지스터를 적재한다.
● device controller은 이 레지스터의 내용에 대해 검토한다. (“키보드에서 문자를 읽어라” 같은 어떤 작업을 할지 결정)
● controller은 장치에서부터 그것의 로컬 버퍼로 데이터를 전달하기 시작한다.
● device controller은 device driver에게 작업이 끝났음을 알린다.
● device driver은 OS의 다른부분에 제어를 넘겨준다. (읽기 작업일 경우, 데이터를 반환하거나 데이터를 가리키는 포인터를 반환)
여기서, controller가 driver에게 작업이 끝났음을 interrupt를 통해 알린다.
1.2.1.1 Overview
하드웨어는 보통 system bus를 통해 CPU에게 언제든지 신호를 전달해서 interrupt를 발생시킨다. (컴퓨터 시스템에는 많은 bus가 있지만, system bus는 주요 구성요소들 간의 주요 소통 통로이다.) interrupt는 많은 목적을 위해 사용되고 OS와 HW가 어떻게 상호작용 하는가에 대해 중요한 부분이다.
CPU가 interrupt 되면, 하던것을 멈추고, 즉시 고정된 위치로 실행을 전이시킨다. 고정된 위치에서는 보통 interrupt에 대한 service routine(컴퓨터에서 특정 이벤트나 인터럽트에 의해 자동으로 호출되는 하위 루틴)이 위치한 시작주소를 포함한다. interrupt service routine의 실행이 완료되면, CPU는 interrupted computation(인터럽트된 계산)을 재개한다.
Interrupt는 computer architecture(컴퓨터 시스템의 구성과 작동 방식을 설계하는 분야)에서 중요한 부분이다. 각 컴퓨터에서는 고유의 interrupt mechanism이 있지만, 몇몇 기능은 공통적이다. interrupt는 제어를 적당한 interrupt service routine으로 전이시킨다. 이러한 전이를 관리하기 위한 직접적인 방법은 interrupt 정보를 시험해보기 위해 generic routine(특정한 작업에 제한되지 않고 여러 상황에서 재사용될 수 있는 일반적인 기능을 수행하는 소프트웨어 코드)을 불러오는 것이다. 이러한 루틴은 interrupt specific handler를 호출한다. 하지만, interrupt는 매우 자주 일어나는 것처럼, 빨리 처리돼야 한다. interrupt routine에 대한 포인터의 테이블을 대신 사용해서 필요한 속도를 제공할 수 있다. Interrupt routine은 테이블을 통해 간접적으로 호출돼서, 중간 루틴은 필요가 없어진다. 일반적으로, 포인터의 테이블은 low memory에 저장된다. 이 위치는, interrput service routine들의 주소를 다양한 기계에서 가지고 있을 수 있다. 이러한 주소의 배열 또는 interrupt vector은 인터럽트 요청과 함께 제공된 고유번호로 indexing 되어, interrupt device에 대한 interrupt service routine의 주소를 제공한다.
1.2.1.2 Implementation
CPU에는 interrupt request line이라는 모든 지시를 실행하면 그것을 감지하는 선이 있다. CPU가 interrupt request line에 신호가 왔음을 controller가 알린것을 감지하면, interrupt number를 읽고 interrupt number을 interrupt vector의 인덱스로 사용하며 interrupt handler routine으로 이동한다. CPU는 그 index와 연관된 주소에서 실행한다. interrupt handler는 작업동안 바뀌는 모든 상태를 저장하고, 필요한 processing을 수행하고, state restore을 실행하고, CPU를 interrupt 이전의 상태로 돌리기 위해 return_from_interrupt 지시를 수행한다. device controller은 interrupt request line에 신호를 줌으로써 interrupt를 발생시키고, CPU는 interrupt를 잡고 interrupt handler에게 보내고 handler은 장치에 servicing 함으로써 interrupt를 clear시킨다.
기본적인 interrupt 메커니즘은 CPU가 동시에 일어나지 않는 이벤트에 대해 device controller가 준비가 됐을 떼. 반응하는 것을 가능하게 하는것이다. 현대의 OS에서는 더 정교한 interrupt handling feature가 필요하다.
- 중요한 processing 중에는 interrupt handling을 미루는 능력이 필요하다.
- 장치를 위한 적당한 interrupt handler를 보낼 수 있는 효과적인 방법이 필요하다.
- OS가 높은 그리고 낮은 우선순위의 interrupt를 구분할 수 있고, 적당한 정도의 긴급성으로 대응할 수 있도록 multilevel interrupt 가 필요하다.
현대의 하드웨어에서는 이러한 세가지 특징을 CPU와 interrupt controller hardware로 제공한다.
대부분의 CPU에서는 nonmaskable interrupt, maskable interrupt 두가지의 interrupt request line이 있다.
nonmaskable은 회복불가한 메모리 에러같은 이벤트에 대해 예약되어 있고, maskable은 interrupt 될 필요 없는 중요한 명령의 실행 전에 CPU에 의해 꺼질 수 있다.
vectored interrupt mechanism의 목적은 single interrupt handler을 줄이는 것이다. 하지만 실제로는, 컴퓨터는 interrupt vector 안의 가지고 있는 주소 element보다 더 많은 장치가 있다. 이 문제점의 해결방안은, interrupt chaining(interrupt vector 안에 있는 각 요소가 interrupt handler의 목록의 헤드를 가리키는것)을 사용하는 것이다. interrupt가 일어나면, 요청을 service할 수 있는 요소가 나타날 때 까지 일치하는 목록에 있는 handler이 하나씩 호출된다. 이러한 구조는 거대한 interrupt table의 오버헤드와 single interrupt handler에 보내는 비효율 사이의 타협접이다.
interrupt mechanism은 interrupt priority levels의 시스템을 구현한다. 이 level은 CPU가 모든 interrupt를 masking 하지 않고, 낮은 우선순위 interrupt를 미룰 수 있고, 높은 우선순위 interrupt가 낮은 우선순위 interrupt의 실행을 선점할 수 있게 한다.
요약하면, interrupt는 현대 OS를 통해 동시에 일어나지 않는 이벤트를 다루기 위해 사용된다. device controller와 하드웨어 결함은 interrupt를 일으킨다. 가장 급한 작업을 먼저 끝나게 해주고, 현대 컴퓨터는 interrupt 우선순위 시스템을 사용한다. interrupt는 시간에 민감한 processing을 위해 사용되므로, 효과적인 interrupt handling은 좋은 시스탬 퍼포먼스를 위해 필요하다.
1.2.2 Storage Structure
범용 컴퓨터들은 대부분의 프로그램을 메인 메모리라고 불리는 rewritable memory로부터 실행한다. 메인 메모리는 대부분 dynamic random access memory(DRAM)이라고 불리는 반도체 기술로 시행된다.
컴퓨터는 다른 형태의 메모리또한 사용한다. 예를들면 컴퓨터 전원을 키기위해 OS를 적재하는 bootstrap program을 실행한다. RAM은 휘발성이므로 RAM이 bootstrap program을 잡고있을 수 없다. 그래서 이를 위해, 그리고 다른 목적을 위해, EEPROM(electrically erasable programmable read only memory)를 사용한다. 다른 형태로는 펌웨어(자주 쓰지 않고 비휘발성인 저장소)를 사용한다. EEPROM은 바뀔 수 있지만, 자주 바뀔수는 없다. 게다가 속도가 느려서 대부분 정적인 프로그램과 데이터를 포함한다. (예를들면, 아이폰에서 serial number와 하드웨어 정보는 EEPROM에 저장)
걱 메모리에는 바이트의 배열이 있고, 각 바이트는 고유의 주소가 있다. 상호작용은 특정 메모리 주소로의 적재 또는 저장명령의 연속을 통해 이뤄진다. 적재명령은 바이트 또는 단어를 메인메모리에서 CPU에 있는 internal register로 옮기는 것이다. 반면 저장 명령은 register의 내용을 메인메모리로 옮기는 것이다. 명백한 적재와 저장 외에는, CPU는 program counter에 저장돼있는 위치로부터 실행하기 위해 메인메모리로부터 자동적으로 명령을 적재한다.
폰노이만 구조에서 전형적인 명령은 처음에 메모리로부터 명령을 가져오고 그 명령을 instruction register에 저장한다. 명령은 디코딩되고 피연산자를 메모리로부터 가져오고 내부 레지스터에 저장되는것을 유발할 수 있다. 피연산자에서의 명령이 실행되고 나면, 결과는 메모리에 저장될 것이다. 메모리 unit은 메모리 주소 스트림만 볼 수 있다. 메모리 unit이 어떻게 만들어졌는지 또는 무엇을 위해서 만들어졌는지 알 수 없다. 따라서 프로그램에 의해 만들어진 메모리 주소가 어떻게 만들어졌는지 무시해도 된다. 우리는 실행되는 프로그램에 의해 만들어진 일련의 메모리 주소에만 관심있다.
이상적으로 우리는 프로그램과 데이터가 메인 메모리에 영원히 있기를 바라지만, 대부분의 시스템에서 두가지 이유로 불가능하다.
● 메인메모리는 필요한 모든 프로그램과 데이터를 영원히 저장하기에는 매우 작다.
● 메인메모리는 휘발성이라 전원이 꺼지거나 손실되면 내용이 사라진다.
따라서 대부분 컴퓨터 시스템에는 2차저장장치가 있다. 2차저장장치의 필요는 많은양의 데이터를 영원히 저장하기 위함에 있다. 대부분의 프로그램은 메모리에 적재되기 전까지 2차 저장장치에 저장된다. 많은 프로그램은 2차 저장장치를 프로그램의 source, 목적으로써 사용한다. 2차저장장치는 메인메모리보다 매우 느리다. 따라서 적절한 2차저장장치의 관리는 컴퓨터시스템에게 매우 종요하다.
더 큰 관점에서, storage structure은 많은 가능한 저장시스템 디자인 중에 한가지이다. 다른 가능한 구성요소는 캐시메모리, CD-ROM, 블루레이, 마그네틱 테이프를 포함한다. 이렇게 충분히 느리고 충분히 커서 특수한 목적(다른 장치에 저장된 내용을 복사해서 저장하는것)에 쓰이는 것들을 3차 저장장치라고 한다.
다양한 저장장치 시스템에서 다른점은, 속도, 크기, 휘발여부에 있다.
일반적으로, 속도와 크기는 반비례 관계이다.
용어에 대한 일반적인 규칙
● 휘발성 저장장치는 메모리라고 불린다.
● 비휘발성 메모리는 NVS라고 하며,우리가 대부분 NVS와 보내는 시간은 2차저장장치와 보낸다. 이 저장장치는 두가지 타입으로 분류된다.
◎ mechanical : 예로 HDD, optical disk, holographic storage, magnetic tape가 있다.
◎ electrical : 예로 플래시 메모리, FRAM, NRAM, SSD가 있다. electrical stroage는 NVM으로 불린다.
mechanical storage는 electrical storage에 비해 일반적으로 더 크고, 바이트당 가격이 더 싸다. 반대로 electrical storage는 비싸고 더 작고 더 빠르다.
전체 storage system의 디자인은 이때까지 말한 요소간의 균형을 맞춰야 한다. 비싼 메모리는 필요한 만큼만 쓰고, 가능한 많은 비용이 들지 않는 비휘발성 저장장치를 사용해야 한다. 캐시는 퍼포먼스를 향상시키기 위해 설치될 수 있고, 접근시간, 전송속도에 대해 큰 차이를 보인다.
1.2.3 I/O Structure
OS 코드의 많은 부분은 I/O를 관리하는 것에 있다. 그것의 의존도에 대한 중요성과 시스템의 퍼포먼스와 장치의 다양한 습성때문이다.
범용 컴퓨터 시스템은 다수의 장치로 구성돼있고, 이들은 common bus를 통해 데이터를 교환한다. interrupt driven I/O의 형태는 적은 양의 데이터를 이동시키는데 적합하지만 NVS I/O와 같은 벌크 데이터를 위해 사용될 때 높은 오버헤드를 발생시킨다. 이 문제점을 해결하기 위해, direct memory access(DMA)가 사용된다. I/O 장치를 위해 buffer, pointer, counter를 세팅한 후, device controller은 CPU의 개입 없이 장치 ,메인메모리에게 또는 장치, 메인메모리로부터 직접적으로 데이터의 전체 블록을 이동한다. 느린 장치를 위해 바이트당 하나의 인터럽트를 발생하는 대신, 블록 하나당 하나의 인터럽트를 만들어내고, device driver에게 작업이 완료됐음을 말한다.
device controller가 이러한 작업을 하는동안 CPU는 다른 작업을 할 수 있다.
어떤 고급 시스템은 bus architecture보다 switch를 사용한다. 이런 시스템에서, 여러개의 구성요소는 공유 bus에서 사이클을 위해 경쟁하기보다, 다른 구성요소와 동시에 상호작용할 수 있다. 이 경우, DMA는 더 효과적이다.
1.3 Computer System Architecture
1.2절에서는 전형적인 컴퓨터 시스템의 일반적인 구조에 대해 설명했다. 컴퓨터 시스템은 여러가지 방법으로 구성될 수 있고, 범용 프로세서가 사용되는 수에 따라 범주가 나눠진다.
1.3.1 Single Processor Systems
과거에는, 대부분의 컴퓨터 시스템들은 하나의 프로세싱 코어를 가지는 하나의 CPU를 가지고 있는 단일 프로세서를 사용했다. 코어는 데이터를 로컬에 저장하기 위한 명령 및 레지스터를 실행하는 구성요소이다. 코어를 가지고 있는 하나의 메인 CPU는 범용 명령 세트를 수행할 수 있고 프로세스로부터 명령을 포함한다. 이러한 시스템들은 다른 특수목적 프로세서들도 포함한다. 디스크, 키보드, 그래픽 컨트롤러같은 장치별 프로세서의 형태로 제공될 수 있다.
이러한 모든 특수목적 프로세서들은 제한된 명령 세트를 실행하고 프로세스를 실행하지 않는다. 가끔 그들은 OS가 특수목적 프로세서에 그들의 다음 작업을 전달하고 그들의 상태를 모니터한다는 점에서 OS에 의해 관리받는다. 예를들어, disk controller microprocessor은 메인 CPU 코어로부터 일련의 요청을 받고, 그것들의 고유 disk queue 그리고 스케쥴링 알고리즘을 실행한다. 이러한 방식은 메인 CPU의 디스크 스케쥴링의 오버헤드를 완화한다. PC들은 키보드에 key storke를 CPU에 보내지는 코드로 변환하는 마이크로프로세서를 가지고 있다. 다른 시스템 또는 환경에서 특수목적 프로세서들은 저레벨 구성요소이다. OS는 이 프로세서들과 소통할 수 없다. 프로세서들은 그들의 업무를 자체적으로 수행한다. 특수목적 프로세서들의 사용은 흔하고 single processor system을 multiprocessor으로 바꾸지 않는다. 한개의 프로세싱 코어를 가진 한가지 범용 CPU 가 있다면 시스템은 single processor system이다. 이러한 정의에 따르면 single processor system인 현대의 컴퓨터 시스템은 없다.
1.3.2 Multiprocessor Systems
전통적으로 시스템은 single core CPU를 가진 두개이상의 프로세서를 가진다. 프로세서는 컴퓨터 버스를 공유하고 가끔 시간, 메모리, 주변장치를 공유한다. multiprocessor system의 원초적인 장점은 증가된 처리량이다.하지만, N개의 프로세서의 속도증가율은 N이 아니고 N보다 작다. 다중 프로세서가 작업을 할 때, 다른 부분들이 올바르게 작동하도록 유지되면 특정양의 오버헤드는 발생한다. 이러한 오버헤드와 공유 자원에 대한 경합은 추가된 프로세서로부터 얻는 이득을 낮춘다.
가장 흔한 multiprocessor system은 각 peer CPU precessor가 운영체제 기능 및 사용자 프로세스를 포함한 모든 작업을 수행하는 symmetric multiprocessing을 사용한다.
이 모델의 장점은 많은 프로세스들이 동시에 실행되면서 퍼포먼스를 급격히 막화시키지 않는 것이다. 하지만 CPU는 분리돼있으므로, 하나는 일을 하지 않고 다른것은 과적되면서 효율적이지 않는 결과를 초래하는 것이다. 이러한 문제는 프로세서가 특정 데이터 구조들을 공유하면 피할 수 있다. 이러한 형태의 multiprocessor system은 프로세스와 자원들이 다양한 프로세서들 사이에서 동적으로 공요될 수 있도록 하고 프로세서들의 작업량 분산을 낮출 수 있다.
multiprocessor의 정의가 진화하면서 하나의 칩에 다중코아가 있는 multicore system을 포함한다. multicore system은 하나의 코어가 있는 여러개의 칩보다 효율적이다. 왜냐하면 칩 내에서의 소통이 침 사이에서의 소통보다 빠르기때문이다. 게다가 여러개의 코어를 가진 하나의 칩이 하나의 코어를 가진 여러개의 칩보다 전력이 적게 들어간다. (모바일 기기에서는 매우 중요)
듀얼코어 디자인에서 각 코어는 자신의 레지스터 세트를 가지고 있고, 로컬 캐시(L1, level1)또한 가지고 있다. level2(L2) 칩에서 로컬이지만 두개의 프로세싱 코어에 의해 공유된다. 대부분 architecture에서 로컬캐시와 공유된 캐시를 결합하는 이러한 방식을 채택한다. 로컬, 저레벨 캐시들은 보통 작고 빠르다(고레벨 공유된 캐시보다).
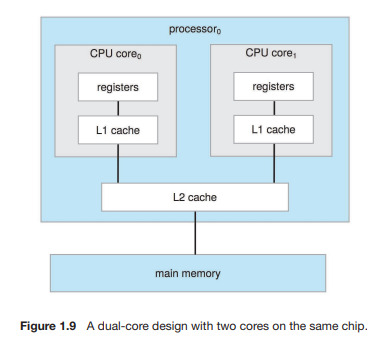
컴퓨터 시스템 구성요소의 정의
● CPU : 명령을 수행하는 하드웨어
● 프로세서 : 하나이상의 CPU를 포함하는 물리적 칩
● 코어 : CPU의 기본적인 계산단위
● 멀티코어 : 같은 CPU에 여러개의 computing core를 포함
● 멀티프로세서 : 여러개의 프로세서 포함
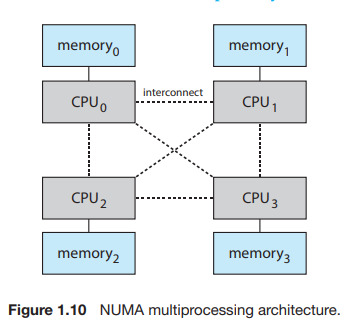
multiprocessor system에 CPU를 추가하는 것은 계산능력을 증가시키겠지만,너무 많은 CPU를 추가하면 시스템버스에 경합이 일어나서 병목현상과 퍼포먼스가 저하된다. 이에대한 대안은 작고 빠른 로컬 버스를 통해 접근되는 자체 로컬 메모리를 각 CPU에 제공하는 것이다. CPU들은 shared system interconnect에 의해 연결되어있고, CPU들은 하나의 물리적 주소공간을 공유한다. 이러한 접근은 non uniform memory access(NUMA)라고 불린다. 장점은 CPU가 로컬 메모리에 접근할 때 속도가 빠를 뿐만 아니라 시스템 상호연결에 있어서 경합도 없다. 따라서 NUMA시스템은 프로세서가 추가됨에 따라 효율적으로 확장할 수 있다.
NUMA시스템의 잠재적 단점은 CPU가 system interconnect를 통해 원격 메모리에 접근해야 할 때 performance penalty를 발생해 지연시간이 증가한다는 것이다. 예를들면 CPU0은 자신의 로컬메모리에 접근하는 것처럼 CPU3의 로컬메모리에 빠르게 접근할 수 없어서 퍼포먼스를 느리게 한다. OS는 CPU 스케쥴링과 메모리 관리를 통해 이런 NUMA penalty를 최소화 할 수 있다. NUMA시스템은 많은 프로세서를 수용하기 위해 확장시킬 수 있으므로 그들은 고성능 컴퓨팅 시스템뿐 아니라 서버에서도 인기를 얻고 있다.
마지막으로 blade server은 다중 프로세서보드, I/O보드, 네트워킹 보드가 동일한 chassis(몸체??)에 배치된 시스템이다. 이 시스템과 전통적인 multiprocessor system의 차이점은 blade processor board는 독립적으로 부트되고 자체의 OS에서 돌아간다. 어떤 blade server board는 멀티프로세서이므로 컴퓨터 타입간 경계가 흐려진다.
1.3.3 Clustered Systems
multiprocessor system의 또다른 타입은 다중 CPU를 함께 모으는 clusterd system이다. Clustered system은 두개 이상의 개별 시스템 또는 노드가 함께 합쳐진다는 점에서 multiprocess system과는 다르다. 각 노드는 보통 멀티코어 시스템이다. 일반적으로 받아들여지는 정의는 clustered computer들은 저장공간을 공유하고 local area network(LAN) 또는 더 빠른 interconnect(InfiniBand같은)으로 긴밀하게 연결돼있다.
클러스터링은 클러스터에 있는 하나이상의 시스템이 실패하더라도 계속 이어나갈 수 있는 high availability service(고가용성)를 제공한다. 고가용성은 많은 응용프로그램에서 중요한 의존도를 높인다. 살아남은 하드웨어의 레벨에 비례하여 서비스를 계속 제공하는 능력을 graceful degradation이라고 한다. 어떤 시스템에서는 graceful degradation을 넘어 fault tolerant 라고 부른다. 왜냐하면 단일 구성요소에 결함이 발생해도 작업을 계속할 수 있기 때문이다.
클러스터링은 비대칭적으로 또는 대칭적으로 만들어질 수 있다.
비대칭적 클러스터링에서는 한 기계가 hot standby mode인 동안 다른 기계에서는 응용프로그램을 실행한다. hot standby host machine에서는 active server를 모니터한다. 서버가 실패한다면 hot standby host는 active server가 된다.
대칭적 클러스터링에서, 두개이상의 호스트가 응용프로그램을 실행하고 서로를 모니터한다. 이 구조는 사용가능한 하드웨어를 모두 사용하므로 명백히 더 효율적이다. 하지만 이것은 실행가능한 응용프로그램 하나 이상을 요구한다.
클러스터는 네트워크를 통해 연결된 몇개의 컴퓨터시스템으로 구성돼있으므로 고사양 컴퓨팅환경을 제공하기 위해 클러스터를 사용할 수도 있다. 이런 시스템은 단일 프로세서나 SMP 시스템보다 뛰어난 계산능력을 가지고 있다. 왜냐하면 클러스터 내의 모든 컴퓨터에서 동시에 응용프로그램을 실행할 수 있기 때문이다. 하지만 응용프로그램은 특히 클러스터를 이용하도록 작성돼야 한다. 이는 프로그램을 클러스터 내의 컴퓨터(들)의 코어에서 병렬적으로 실행되는 분리된 구성요소들로 나누는 parallelization이라고 하는 기술과 관련돼있다.
1.4 Operating System Operations
1.4.1 Multiprogramming and Multitasking
OS는의 가장 중요한 측면 중 하나는 여러 프로그램을 실행할 수 있는 것이다. multiprogramming 은 CPU가 항상 하나의 프로그램을 실행할 수 있도록 구성, CPU이용률을 높인다. Multitasking은 multiprogramming의 논리적 확장이며 multitasking system에서 CPU는 프로세스들을 전환하며 여러 프로세스를 실행하지만 전환이 자주 일어나서 사용자에게 빠른 반응시간을 제공한다.
1.4.2 Dual Mode and Multimode Operation
OS와 사용자는 하드웨어, 소프트웨어 자원을 공유하기 때문에 부적절한 어떤 프로그램이 다른 프로그램 또는 운영체제가 부적절하게 작동하지 않도록 보장해야한다. 이를 위해선 운영체제 코드실행, 사용자-정의 코드 실행을 구분할 수 있어야 한다.
최소 두개의 연산 모드, 사용자모드와 커널모드가 필요하다. 모드비트는 커널모드일 경우 0, 사용자모드일 경우 1을 나타낸다.
1.5 Resourcement Management
1.5.1 Process Management
프로세스는 실행중인 프로그램이다. 하지만 프로그램 그 자체는 프로세스가 아니다. 하나의 프로그램은 수동적 개체지만, 프로세스는 프로그램 카운터(실행중인 명령어 주소를 가리키는 레지스터)를 가진 능동적인 개체이다. 프로세스는 작업을 수행하기 위해 CPU, 메모리, I/O, 파일, Initialization data가 필요하다. 프로세스를 종료하려면, 재사용 가능한 자원을 회수해야 한다. Single threaded process는 다음에 실행할 명령어의 위치를 특정하는 하나의 program counter를 가진다. 프로세스는 종료 전까지 명령들을 순차적으로 한번에 하나씩 실행해야 한다. multi threaded process는 하나의 thread당 하나의 program counter를 가진다. 전형적인 시스템은 많은 프로세스를 가지고, 어떤 사용자, 어떤 OS에 따라서는 하나 이상의 CPU에서 동시에 실행된다.
OS는 프로세스 관리와 관련해 다음과 같은 일을 한다.
● 사용자 프로세스, 시스템 프로세스의 생성과 제거
● CPU에 프로세스와 스레드 스케쥴하기
● 프로세스의 연기와 재개
● 프로세스 동기화를 위한 메커니즘 제공
● 프로세스 통신을 위한 메커니즘 제공
● deadlock handling을 위한 메커니즘 제공
1.5.2 Memory Management
프로그램을 실행하기 위해서는, 명령의 모든(또는 일부) 명령어가 메모리에 있어야 한다. 그리고 프로그램이 필요로 하는 모든(또는 일부) 데이터도 메모리에 있어야 한다. 특정 시스템에 대한 메모리 관리 기법의 선택은 여러 요인에 의해 결정되지만, 하드웨어 설계에 좌우된다.
운영체제는 메모리 관리와 관련해 다음과 같은 일을 한다.
● 메모리의 어느 부분이 사용되고 있는지, 어느 프로세스에 의해 사용되고 있는지 추적
● 필요에 따라 메모리 공간을 할당하고 회수
● 어떤 프로세스들을 메모리에 적재하고 제거할 것인지 결정
1.5.3 File System Management
OS는 저장장치의 물리적 특성을 추상화하여 논리적인 저장단위인 파일을 정의한다. 컴퓨터는 여러가지 물리적 매체에 정보를 저장할 수 있으며, 각 매체는 디스크 드라이브 같은 장치의 통제를 받는다. 그리고 장치마다 접근속도, 용량, 데이터 전송률, 접근방식 등 다양한 속성이 있다.
파일은 디렉토리들로 구성되어 있고, 운영체제는 파일 관리를 위해 다음 작업을 담당한다.
● 파일의 생성 및 제거
● 디렉토리 생성 및 제거
● 파일과 디렉토리를 조작하기 위한 primitive 제공
● 파일을 보조저장장치로 매핑
● 안정적인(비휘발성) 저장매체에 파일을 백업
1.5.4 Mass Storage Management
보통 디스크는 메인메모리에 적합하지 않거나 오랜기간 보관해야 하는 데이터를 저장할 때 사용한다. 컴퓨터 연산의 속도는 disk subsystem, 알고리즘에 달려있다. OS는 보조저장장치 관리와 관련하여 다음 작업을 담당한다.
● 마운팅과 언마운팅
● 사용 가능 공간 관리
● 저장장소 할당
● 디스크 스케줄링
● 저장장치 분할
● 보호
1.5.5 Cache Management
정보가 사용됨에 따라, 더 빠른 장치인 캐시에 일시적으로 복사된다. 특정 정보가 필요할 때, 캐시에 그 정보가 있는지 확인한 후, 캐시에 잇으면 직접 사용하고, 캐시에 없다면 메인 메모리 시스템으로부터 그 정보를 가져와서 사용하며 이때, 이 정보가 다시 사용될 확률이 높다고 가정해 캐시에 넣는다.
캐시의 크기는 제한되어 있으므로 잘 관리해야 성능을 높일 수 있다. 캐시의 크기와 교체 정책을 잘 선택하면 원하는 데이터가 캐시에 있을 확률이 매우 높아진다.
저장장치의 수준별로 접근속도가 천차만별이기에 캐시와 하위 storage의 내용은 서로 다를 확률이 높다. -> coherency
Chapter Objectives
- ● 컴퓨터 시스템의 일반적인 구성과 interrupt의 역할을 설명
컴퓨터 시스템은 하드웨어와 소프트웨어로 구성되어 있다. 하드웨어는 중앙처리장치(CPU), 기억장치, 입출력장치, 버스 등의 구성요소로 이루어져 있다. 소프트웨어는 운영체제(OS)와 응용프로그램으로 이루어져 있다.
interrupt는 하드웨어가 보내는 신호로, CPU가 현재 실행하고 있는 작업을 멈추고 해당 interrupt에 대응하는 interrupt handler를 실행하도록 한다. interrupt는 입출력장치, 타이머, 예외상황 등에서 발생하며, CPU의 작업을 즉시 중단시키고 빠르게 처리해야하는 상황에서 사용된.
- ● 현대의 multiprocessor computer system의 구성요소에 대해 설명
현대의 multiprocessor computer system은 여러 개의 CPU를 포함하며, 공유메모리와 공유통신망으로 이루어져 있다. 각 CPU는 자신의 캐시와 메모리를 가지고 있으며, 이를 통해 메모리 공유를 최소화하고 시스템 성능을 향상시킨다. 또한, 공유메모리와 공유통신망은 CPU들 간의 데이터 공유와 통신을 가능하게 한다.
- ● user mode에서 kernel mode로의 전환에 대해 설명
운영체제(OS)는 보안을 유지하기 위해 user mode와 kernel mode로 구분된다. 일반적으로 응용프로그램은 user mode에서 실행되며, 이 때는 자신이 사용할 수 있는 시스템 자원이 제한된다. 하지만, 특정 시스템 자원에 접근하기 위해 kernel mode로 전환해야하는 경우가 있다. 이 때는 CPU가 현재 실행중인 작업을 중지하고 OS의 코드를 실행하도록 한. 이를 system call이라고도 한다.
- ● OS가 다양한 컴퓨팅 환경에서 어떻게 사용되는지 논의
OS는 문제를 풀기 위해 요구되는 자원들을 할당하는 자원 할당자의 기능과 오류 및 부적절한 컴퓨터의 사용을 막기위한 통제 프로그램의 기능을 하며, 멀티 프로그래밍, 멀티태스킹을 할 수 있게 해주고 프로세스 관리, 메모리 관리, 파일시스템 관리, 저장장치 관리, 캐시관리 등의 역할들 한다
- ● 오픈소스 OS의 예
가장 대표적인 예로 리눅스가 있고, FreeBSD, OpenBSD, NetBSD, Android등이 있다.
댓글남기기