3/7 LLaMA 논문 용어정리
LLaMA 논문 정리 게시물에서 처음듣는 단어나 개념을 정리하려고 한다.
- BPE(Byte pair encoding) 알고리즘 :
BPE는 데이터 압축 알고리즘이다. 예를 들어.
aaabdaaabac
라는 문자열에 대해 BPE를 수행한다고 하자. BPE는 연속적으로 가장 많이 등장한 문자의 쌍을 찾아서 하나의 글자로 압축하는 방식이다.
Z = aa
ZabdZabac
처음 주어진 문자열을 다음과 같이 변형할 수 있다. 이를 반복하면
Y = ab
Z = aa
ZYdZYac
마지막으로
X = ZY
XdXac
더이상 두번 이상 등장한 문자의 쌍이 없으므로 BPE를 수행한 결과는 XdXac가 된다.
실제 사용하는 예시를 살펴보면(단어의 오른쪽 숫자는 등장한 빈도수)
-
l o w : 5 l o w e r : 2 n e w e s t : 6 w i d e s t : 3 단어집합 : l, o, w, e, r, n, s, t, i, d, es -
총 9번 등장한 e와 s를 압축 l o w : 5 l o w e r : 2 n e w es t : 6 w i d es t : 3 단어집합 : l, o, w, e, r, n, s, t, i, d, es, est -
7번 등장한 l, o 압축 l o w : 5 l o w e r : 2 n e w est : 6 w i d est : 3 단어집합 : l, o, w, e, r, n, s, t, i, d, es, est, lo -
위 과정을 포함해서 총 10번 수행하면 low : 5 low e r : 2 newest : 6 widest : 3 단어집합 : l, o, w, e, r, n, s, t, i, d, es, est, lo, low, ne, new, newest, wi, wid, widest
만약 BPE를 수행하지 않았다면 단어집합은 {low, lower, newest, widest}이므로 만약 lowest같은 단어가 나온다면 모델은 대응을 할 수 없으므로 OOV(Out Of Vocabulary)에 넣게된다.
-
UTF-8
-
유니코드
초기 컴퓨터는 영어와 몇개의 특수문자만을 사용했는데, 이를 컴퓨터에 저장하기 위해서 1byte의 공간으로 충분히 저장할 수 있었다. 그러나 영어권이 아닌 국가의 사람들도 컴퓨터로 자신들의 모국어를 사용하고 싶어 했다. 이를 위해 전세계 언어를 모두 표시할 수 있는 국제표준코드를 만들었는데 이것이 유니코드이다.
코드표를 만들었다면 이 코드표를 컴퓨터에 어떻게 저장할 것인지(Encoding)가 문제이다. UTF 인코딩 방식으로 UTF-8, UTF-16, UTF-32 등이 있고 UTF 뒤의 숫자는 한 문자를 인코딩하는 길이로 UTF-8은 유니코드 문자를 8bit 값으로 인코딩한다는 의미이다.
UTF-8은 가변 인코딩 방식 즉, 글자마다 컴퓨터가 표현하는 길이가 다르다는것을 의미한다. ASCII문자들은 그대로 1byte, 중동, 유럽의 언어들은 2byte, 한국을 포함한 아시아권 언어들은 3byte이상을 필요로 한다.
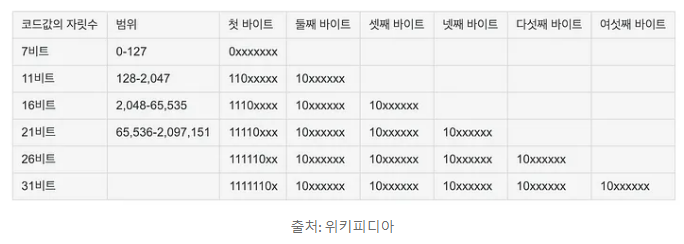
-
-
Rotary Positional Embedding(RoPE)
-
SwiGLU 활성화함수
SwiGLU 함수는 Swish 함수와 GLU 함수를 합쳐 만든 활성화함수이다.
-
Swish 활성화함수 \(Swish(x)\ =\ x\sigma(\beta x)\\ where\ \sigma(x)={\frac{1}{1+e^{-x}}}\\ \beta\ :\ learnable\ parameter\)
-
GLU 활성화함수 \(GLU(x,\ W,\ V,\ b,\ c)\ =\ \sigma(xW+b) \times\ (xV+c)\)
- W, V : 학습 가능한 가중치
- b, c : 학습가능한 bias
- x(곱하기) : Element-wise multiplication
-
SwiGLU 활성화함수 \(SwiGLU(x,\ W,\ V,\ b,\ c,\ \beta)\ =\ Swish_{\beta}(xW+b)\times(xV+c)\)
-
-
AdamW
-
Cosine learning rate schedule
학습률 大 => 발산
학습률 小 => global optima에 도달하는데 시간이 많이 걸림. local optima에 빠질수 있다.
학습률을 어떻게 설정하는지를 learning rate schedule이라고 하는데 코사인 함수를 이용하는 방법을 Cosine learning rate schedule이라고 한다. 우선 공식은 다음과 같다. 사용자가 세팅해야 할 하이퍼파라미터는 $a_{0}, T$ 두개라서 설정할 하이퍼파라미터가 적고 학습률이 연속적으로 변한다는 장점이 있다. \(a_{t} = \frac{1}{2}a_{0}(1+cos(t\pi/T))\)
-
Gradient Checkpointing
Gradient Checkpointing은 딥러닝 모델에서 역전파과정 중에 메모리 사용량을 절감하기 위해 생겨난 기법이. 구체적으로 중간 계산 결과를 저장해놓고 나중에 필요할 때 다시 계산을 하는 방식이다. Gradient Checkpointing은 메모리 사용량을 줄이면서 모델학습을 가능하게 하며 대규모 모델, 시퀀스 길이가 긴 경우 유용하다.
-
maj1@k
k>1개의 솔루션들을 샘플링해서 majority vote로 하나의 가장 일반적인 답변을 선택하는 방법이다.
-
과반수 투표(majority vote)
여러개의 분류기를 하나의 분류기로 연결하는 기법인 앙상블 기법에서 분류기의 과반수가 예측한 클래스 레이블을 선택하는 방법을 과반수 투표(majority vote)라고 한다.
-
majn@k
majn@k는 maj1@k의 일반화된 버전으로 n개의 가장 일반적인 답변을 선택하는 방법이다.
-
-
pass@k
pass@k metric은 모델이 k>1개의 솔루션들을 샘플링한 후 이 중 하나라도 문제를 해결하면 맞다고 ㅏ는 지표이다.
댓글남기기