4/17 Llama2 한영번역기 파인튜닝
저번에 LSTM셀로 이루어진 seq2seq모델로 번역기를 만들려고 했지만 실패했다. 이번에는 Llama2를 이용해 번역기를 만들어보자. 우선 저번에 사용했던 한국어-영어 번역 말뭉치를 사용한다..
데이터 정제
데이터를 Llama2에 파인튜닝하기 적합한 형태로 만들어주기 위해 .json파일로 정제작업을한다. 정제작업이 끝난 json파일의 앞 3줄만 가져와보면 다음과 같다.
# "text" : 프롬프트 ### 한국어 ### 영어
[
{"text": "Korean and English sentences are given in order below. Translate Korean sentences into English sentences. ### Korean : 이번 신제품 출시에 대한 시장의 반응은 어떤가요? ### English : How is the market's reaction to the newly released product?"},
{"text": "Korean and English sentences are given in order below. Translate Korean sentences into English sentences. ### Korean : 판매량이 지난번 제품보다 빠르게 늘고 있습니다. ### English : The sales increase is faster than the previous product."},
{"text": "Korean and English sentences are given in order below. Translate Korean sentences into English sentences. ### Korean : 그렇다면 공장에 연락해서 주문량을 더 늘려야겠네요. ### English : Then, we'll have to call the manufacturer and increase the volume of orders."}
]
수행하고자 하는 작업에 대한 프롬프트, 한국어, 영어 순으로 이루어진 딕셔너리들로 이루어진 리스트로 만들었다.
파인튜닝
파인튜닝은 huggingFace의 auto train 모듈을 사용했고 모델은 TinyPixel/Llama-2-7B-bf16-sharded을 사용했다. 전체 코드는 깃허브에 올려놓았다.
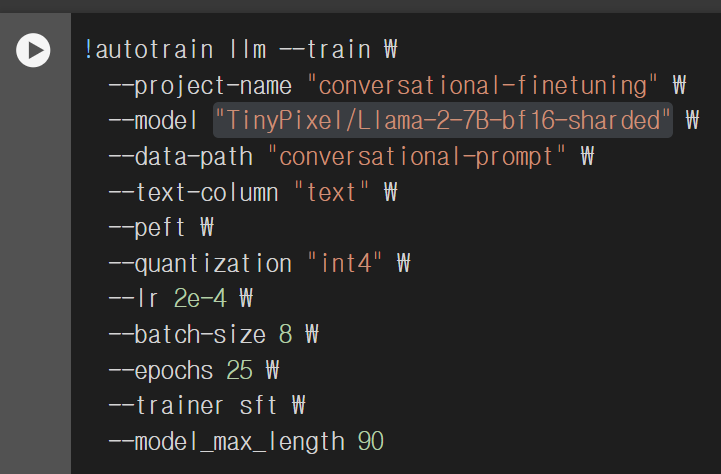
번역 결과
번역문에서 나타난 문제점이 한국어를 영어로 번역하지 않고 한국어로 출력되는 현상이 나타났다.
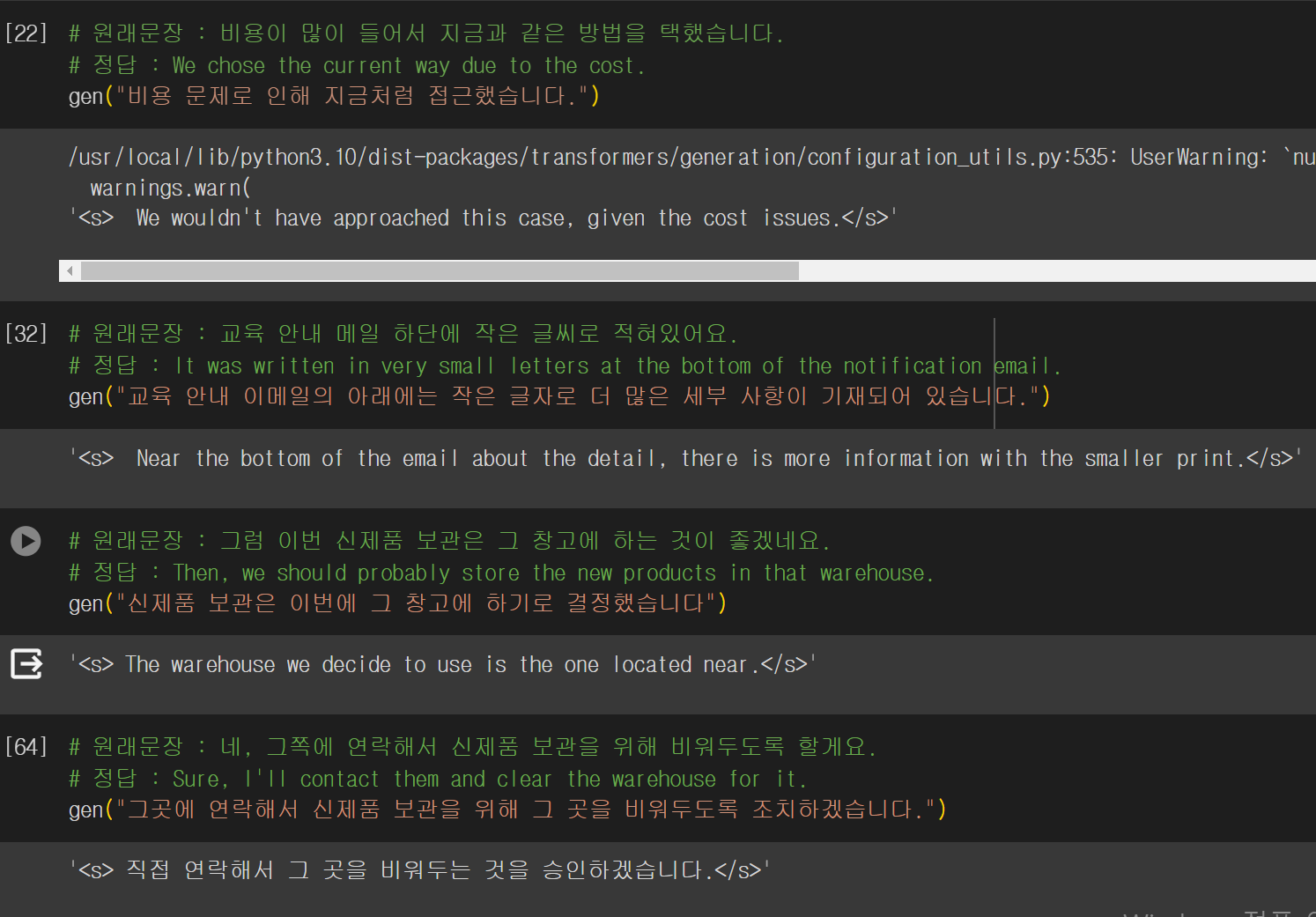
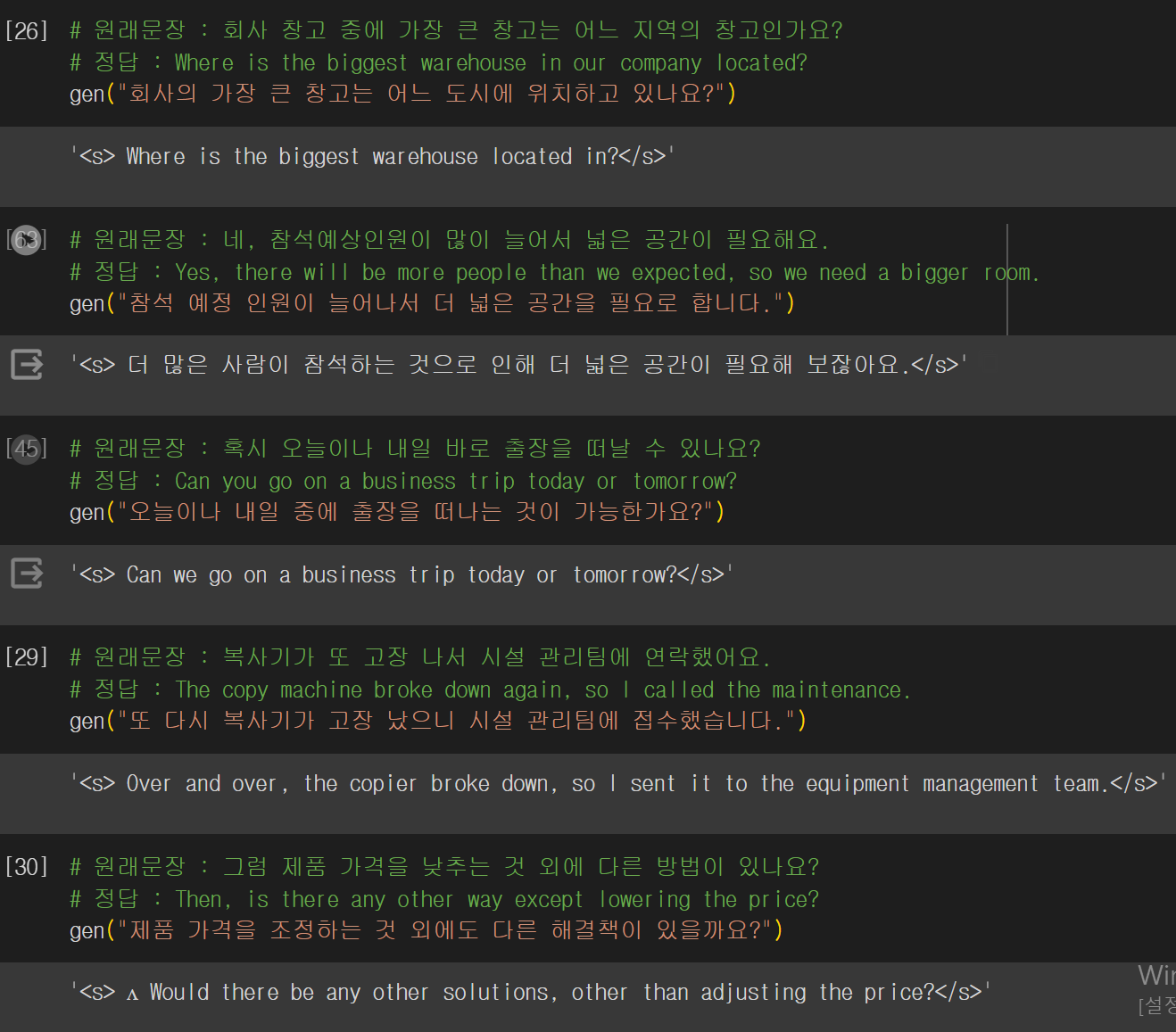

영어로 어느정도 잘 번역된 문장도 있고 매끄럽지 못한 문장도 있었다. 에폭수를 늘리고 다시 학습을 시켰지만 여전히 한국어로 출력되는 문제는 발생했다.
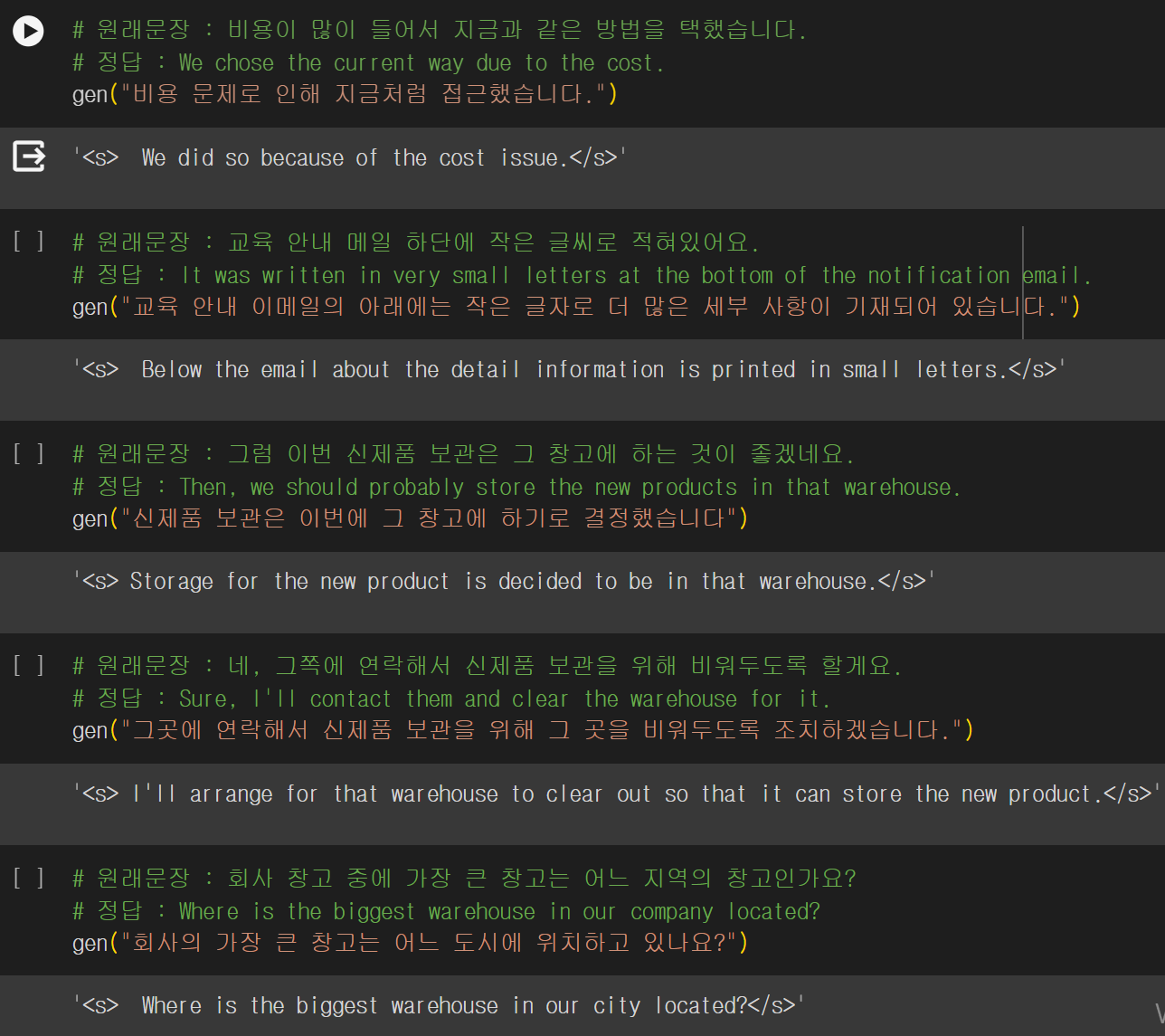
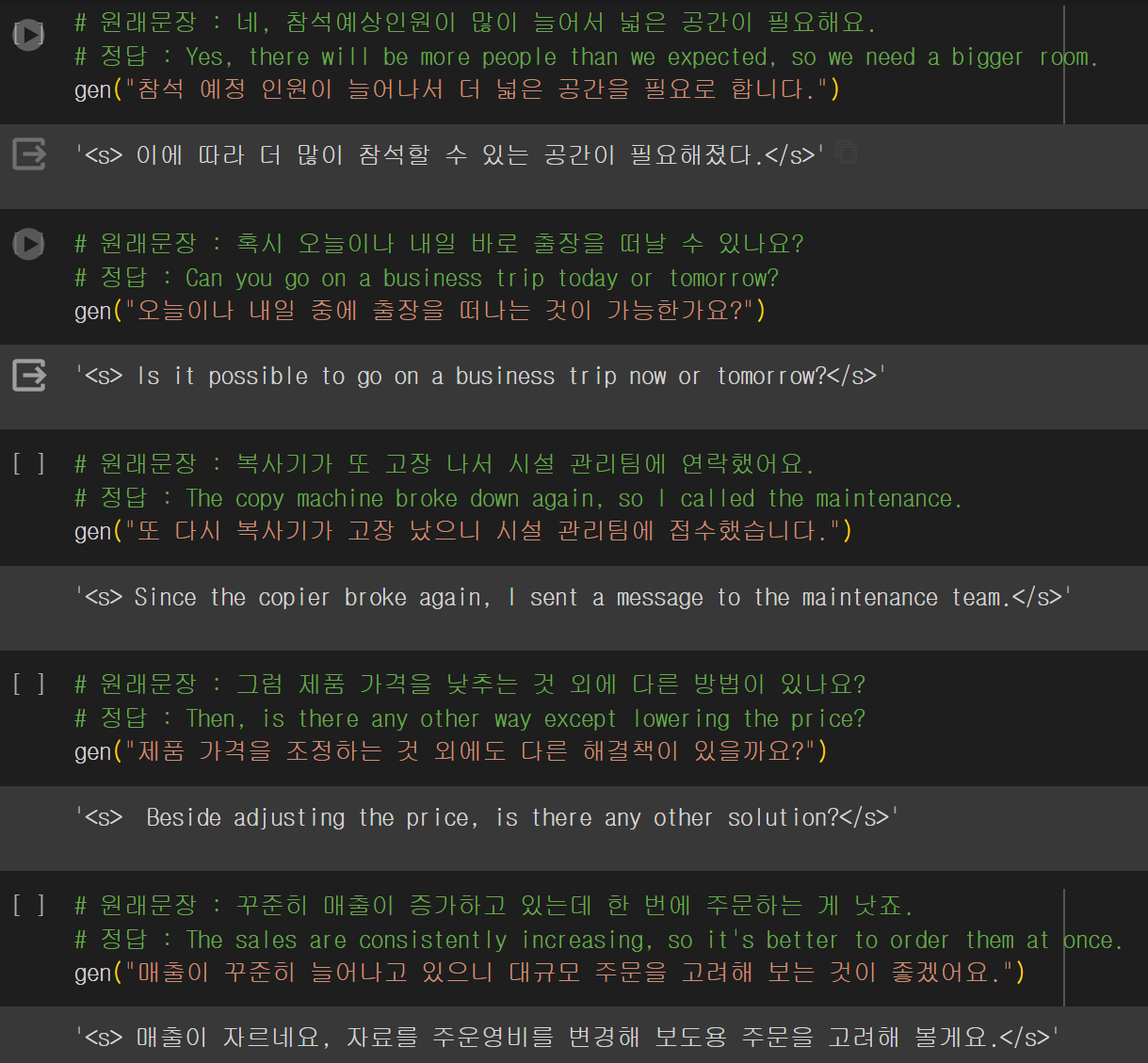
하이퍼파라미터를 몇번의 수정을 계속 해봤지만 드라마틱하게 나아지지는 않았다. 위에 사진에서는 10개문장중 2~3개 문장이 한국어로 출력되었지만(저것도 그나마 잘 나온편이었다.) 하이퍼파라미터를 수정을 할수록 결과가 더욱 이상해졌다.
다른 Llama2 파인튜닝한 코드들을 살펴보다가 프롬프트가 잘못된것 같아 다음과 같은 형태로 수정을 해주었다.
{Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.### Instruction : Korean and English sentences are given in order below. Translate Korean sentences into English sentences.### Korean : 이번 신제품 출시에 대한 시장의 반응은 어떤가요? ### English : How is the market's reaction to the newly released product?}
데이터와 프롬프트를 모두 수정을 하고 학습을 한 결과 이전보다 한국어 문장이 훨씬 덜 출력되었다.
출력결과
입력 문장 데이터는 크게 3가지 방식으로 실험했다.
- 훈련 데이터 중 임의로 선택해 augment + 훈련데이터에 포함되지 않은 데이터 중 임의로 선택 => 출력 결과와 정답 간의 bleu score 측정
- 챗gpt가 임의로 생성한 문장 => 구글 번역기에서 나온 결과를 정답으로 해서 bleu score 측정
- 훈련 데이터에서 임의로 문장을 선택 => 구글 번역기의 score와 Llama의 score 비교
방법1
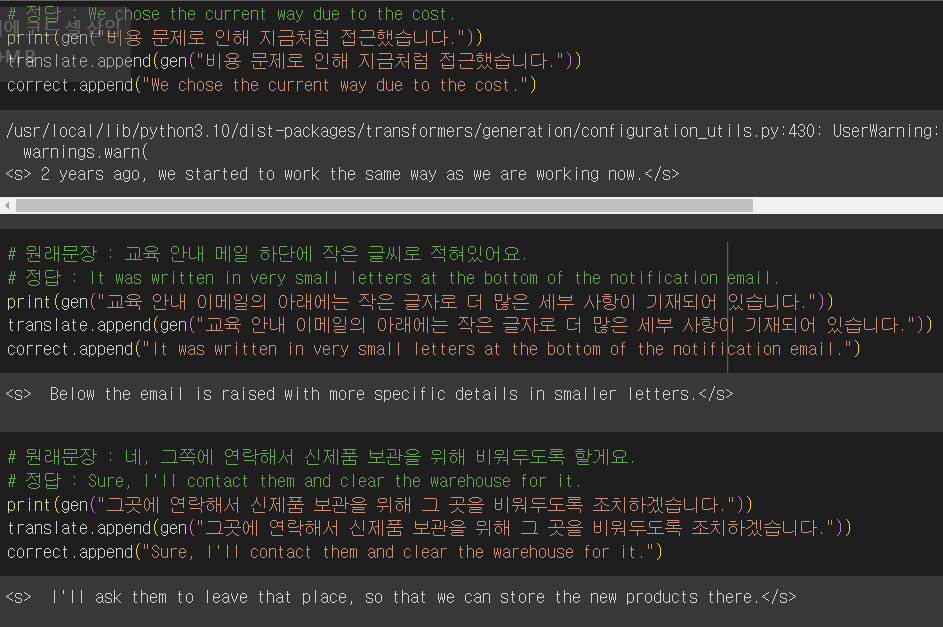
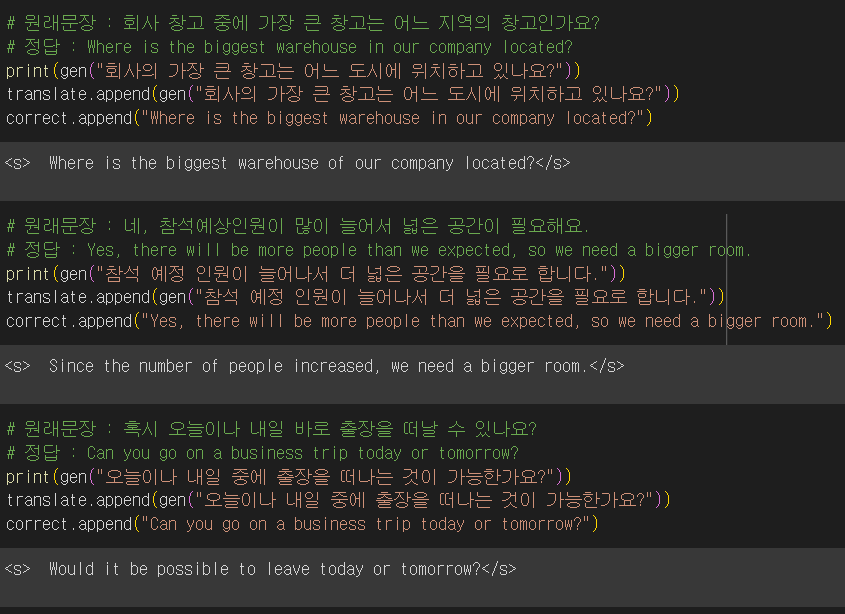
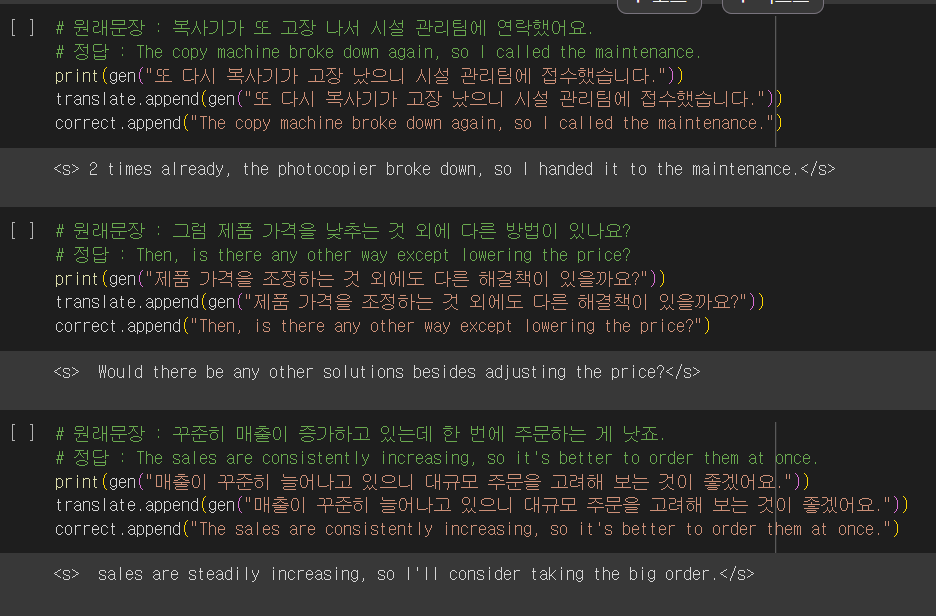
BLEU score
출력 결과에 시작과 끝에 있는 토큰을 삭제한 뒤 BLEU score를 측정했다.

방법2

BLEU score
ChatGPT에게 10개의 문장을 받은 뒤 수동으로 구글 번역기로 번역결과를 얻어냈다. 정답 레이블을 구글 정답으로 간주하고 BLEU score를 측정했다.

방법3
random 라이브러리를 이용해 훈련데이터에 포함된 문장 20개를 랜덤으로 추출해서 구글 번역기와 비교했다.
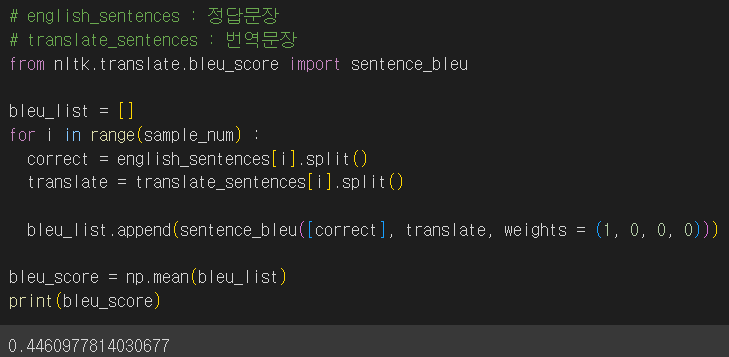

구글 번역기에서 출력된 문장은 0.39점, 파인튜닝한 모델의 점수는 0.45점으로 더 높게 나왔다.
댓글남기기