[LLM] 해부학 PDF 질의응답 RAG W13-16
W13
학습용 Q&A 데이터셋 구축 방법
1. 문서 구조 기반 QnA 생성
- 제목-내용 : 각 섹션 제목을 질문으로, 내용을 답변으로 변환
- 정의 질문 : “~은 무엇인가?” → 해당 정의 & 설명
- 절차 질문 : “~하는 방법은?” → 단계별 설명
2. 비지도 학습 기법
- Masked Language Modeling : 문장에서 임의의 단어를 마스킹하고 모델이 예측하도록 훈련
- Next word prediction : 이전 단어를 바탕으로 다음 단어를 예측하는 방식
LLM 훈련 데이터셋 개선 방안(데이터 구축 이후 적용가능)
1. Preference Datasets :
기존 답변들의 품질, 선호도 평가하는 방식
- 투표 데이터 : 인간이 선호하는 답변을 투표
- 모델 간의 평가 : 여러 LLM이 생성한 답변을 비교하여 가장 좋은 답변을 선택
- 점수 데이터 : 인간이나 모델이 답변에 점수를 매기고, 이를 학습시킴
2. Data Evolution
기존 instruction을 변형, 확장하는 방식
- In Depth Evolving : 단순한 Instruction을 더 상세하고 복잡하게 발전
- In Breadth Evolving : 새롭고 다양한 Instruction 생성
- Elimination Evolving : 효과적이지 않은 Instruction 제거
3. Constitutional AI
모델의 유해한 응답을 방지하기 위한 방식
Phase 1 : Supervised Learning
- 해로운 질문 생성 : 모델에게 해로운 질문을 함
- 초기 응답 : 해로운 응답 생성
- self-critique : 원칙에 따라 자신의 응답을 비판
- Revision : 비판을 바탕으로 개선된 응답 생성
- Fine Tuning : 개선된 응답으로 모델 재훈련
Phase 2 : Reinforcement Learning
- Response pair 생성 : 같은 질문에 대해 두개의 응답 생성
- AI Evaluation : 원칙에 따라 어느 응답이 더 나은지 AI가 판단
- Preference Model 훈련 : AI 선호도로 reward 모델 훈련
- RLAIF : Reinforcement Learning from AI Feedback로 최종 모델 훈련
QnA 데이터셋 구축 프로세스
파인튜닝 코드 개발
적용 기법
- QLoRA
- r=16 : LoRA rank - 저차원 분해 행렬의 차원 크기
- lora_alpha=32 : LoRA 스케일링 벡터 - 학습률 조정용
- target_modules : LoRA를 적용할 모듈(query, value, key, output)
- lora_dropout=0.1 : LoRA 레이어의 dropout 비율
- bias=”none” : bias 파라미터 학습 방식(none : bias는 학습하지 않음)
- task_type=”CAUSAL_LM” : 태스크 타입 - 인과적 언어 모델링
- 구현은 했지만 멀티 GPU를 사용해 학습시키지는 못함
- LoftQ
- loftq_bits=4 : 4비트 양자화 사용
- loftq_iter=1 : LoftQ 초기화 반복 횟수
- init_lora_weights=”loftq” : LoRA 가중치를 LoftQ 방식으로 초기화
- loftq_config=loftq_config : LoftQ 설정 적용
- DataCollator
- 여러 개의 개별 샘플들을 하나의 배치로 묶어주는 역할
- 학습시 배치 단위로 데이터 처리
- mlm(Masked Language Modeling)
- False : 인과적 언어 모델링 사용(GPT 스타일)
- True : 마스크된 언어 모델링 사용(BERT 스타일)
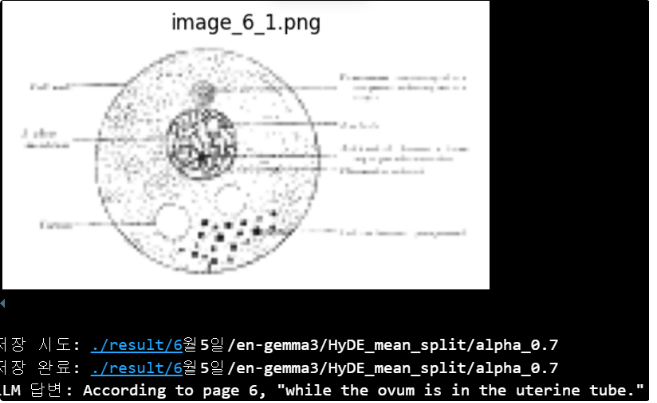
이미지 출력
로직
- 답변에 “~페이지에 따르면…”, “According to page ~…”에서 페이지 정보를 추출
- 해당 페이지 정보를 key로 존재하는 이미지를 출력하는 형태
- 아키텍처
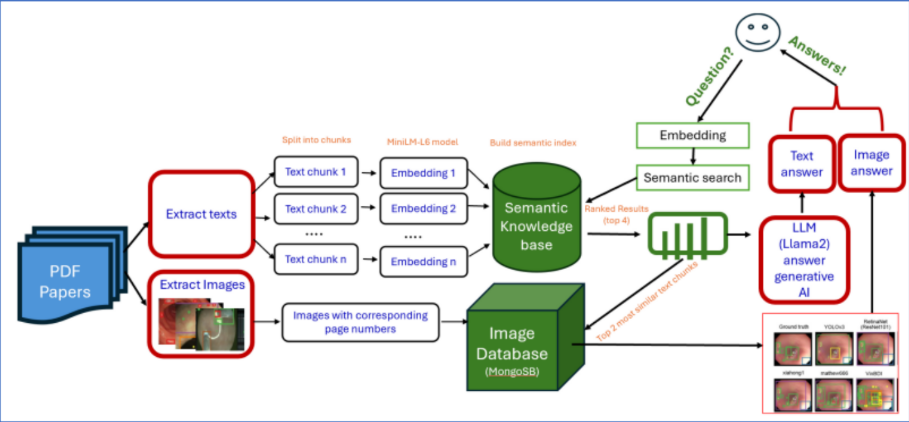
- 결과
파인튜닝 관련 파라미터 옵션
test_0604_QLoRA.ipynb
- LoRA 설정
- r=4, 8, 16, 32, 64, 128 : 어댑터 크기
- 작을수록 메모리 절약, 학습 속도 빠름, 표현력 제한
- 클수록 메모리 많이, 과적합 위험, 표현력 증가
- lora_alpha : LoRA 스케일링 팩터
- 일반적으로 r의 1~4배 설정
- 클수록 LoRA 가중치 영향력 증가
- target_modules : LoRA 적용할 모듈
- 기본 : [“q_proj”, “v_proj”]
- attention 전체 : [“q_proj”, “v_proj”, “k_proj”, “o_proj”]
- FFN까지 : [“q_proj”, “v_proj”, “k_proj”, “o_proj”, “gate_proj”, “up_proj”, “down_proj”]
- lora_dropout=0.0, 0.05, 0.1, 0.2, 0.3 : LoRA 드롭아웃 비율
- 과적합 방지 vs 학습 능력 tradeoff
- bias=”none”, “lora_only”, “all” : 편향 학습 설정
- task_type : 태스크 타입
- r=4, 8, 16, 32, 64, 128 : 어댑터 크기
- TrainingArguments 설정
- per_device_train_batch_size=1, 2, 4, 8 : 디바이스당 배치 크기
- gradient_accumulation_steps=1, 2, 4, 8, 16, 32 : 그래디언트 누적 스탭(메모리 절약을 위해 8번 나눠서 처리)
- num_train_epochs=1, 2, 3, 5, 10
- learning_rate=1e-5, 5e-5, 1e-4, 2e-4, 5e-4, 1e-3
- fp16=True, False or bf16=True, False : 메모리 사용량을 절만으로 줄이고 학습 속도 향상, 정밀도 약간 떨어짐
- warmup_steps=0, 50, 100, 200, 500 : 초기에 학습률을 점진적으로 증가 → 학습 안정성 확보
- lr_scheduler_type=”linear”, “cosine”, “cosine_with_restarts”, “polynomial”, “constant”, “constant_with_warmup” : 학습 스케줄러 타입 → 학습 후반부로 갈수록 학습률을 코사인 형태로 감소시켜 세밀한 최적화
- remove_unused_columns=True, False : 불필요한 컬럼을 제거하지 않음
- dataloader_pin_memory=True, False : 데이터 로딩이 좀 더 느리지만 시스템 메모리 절약
- DataCollatorForLanguageModeling
- mlm : masked language modeling 사용 여부
- True : Bert 스타일
- False : GPT 스타일
- dataloader_num_workers=0, 1, 2, 4 : 데이터로더 워커 수
- ddp_find_unused_parameters=True, False : 분산학습시 사용하지 않는 파라미터 찾기
- mlm : masked language modeling 사용 여부
test_0604_loftQ.ipynb
- LoftQ
- loftq_bits=2, 4, 8 : 몇비트 양자화 사용할지
- loftq_iter=1, 2, 5, 10 : LoftQ 초기화 반복 횟수
W14
DoRA 기법 구현
목적
- LoRA는 모든 가중치에 동일한 방식으로 가중치 업데이트 적용
- 가중치 행렬을 크기와 방향으로 분해하여 미세조정 적용
장점
- 크기와 방향을 분리 → 더 효과적으로 모델 튜닝 가능함
- 크기를 독립적으로 조절 → 안정적인 튜닝
- 적은 파라미터 수 유지 → 파인튜닝된 모델의 저장 공간 부담이 적다
SLearnLLM
- 설명
- 링크
- 학습용 데이터셋의 질문을 LLM이 알고 있는지 미리 판단
- 질문에 대한 LLM의 답변을 받은 후, 정답과 일치하지 않는 경우 추가적으로 학습
- 단독으로 LLM judge를 했을 경우, 실수가 발생 → 5개의 소형 LLM을 이용해 다수결 투표를 진행
- 결과
- 30개의 오답 질문-답변 중 23개의 오답을 모호하다고 판단
KAG
- 구현된 코드가 없고, 공식 깃허브만 존재
KG-RAG
- KAG와 마찬가지로 지식 그래프 구조를 사용
- 작동 방식
- 질문 분석 : 사용자 질문을 분석하여 핵심 엔티티(개념, 사물)와 관계를 파악
- 지식 그래프 검색 : 파악된 엔티티와 관계를 바탕으로 지식 그래프에서 관련성 높은 정보 검색
- 정보 증강 : 검색된 지식 그래프 정보를 텍스트 형태로 반환하여 입력 프롬프트에 추가
- 답변 생성 : LLM이 증강된 정보를 바탕으로 답변 생성
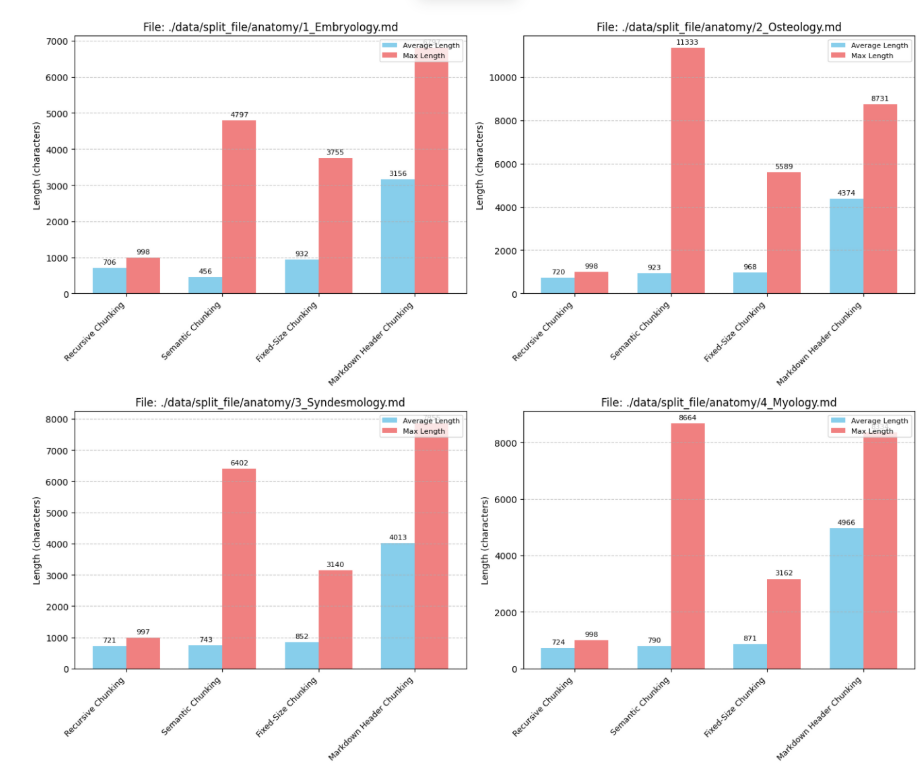
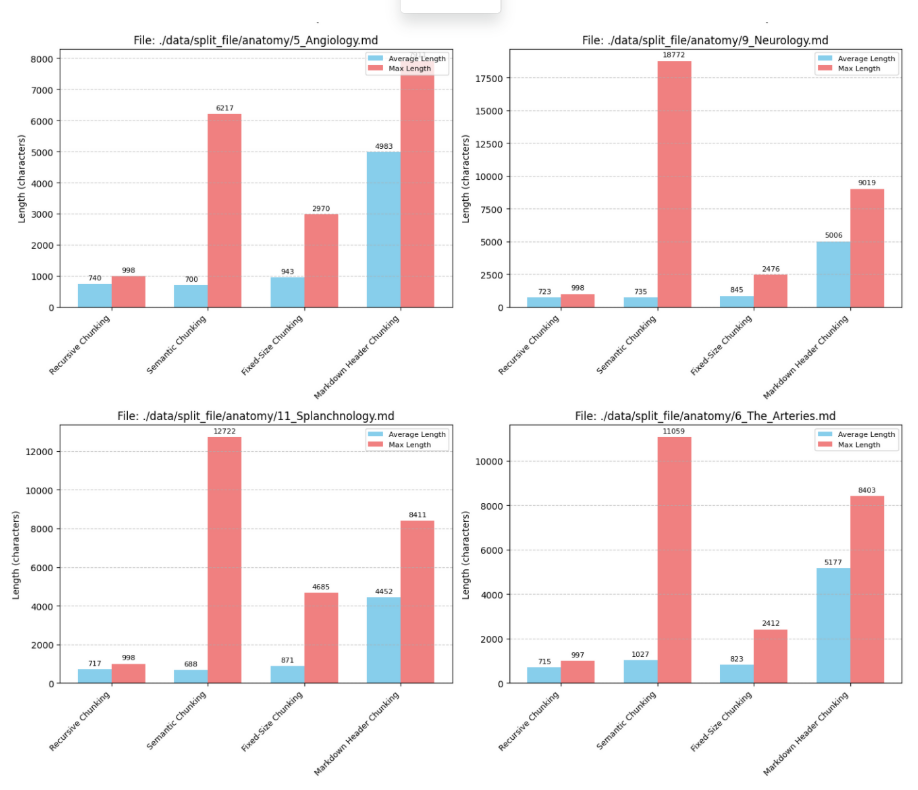
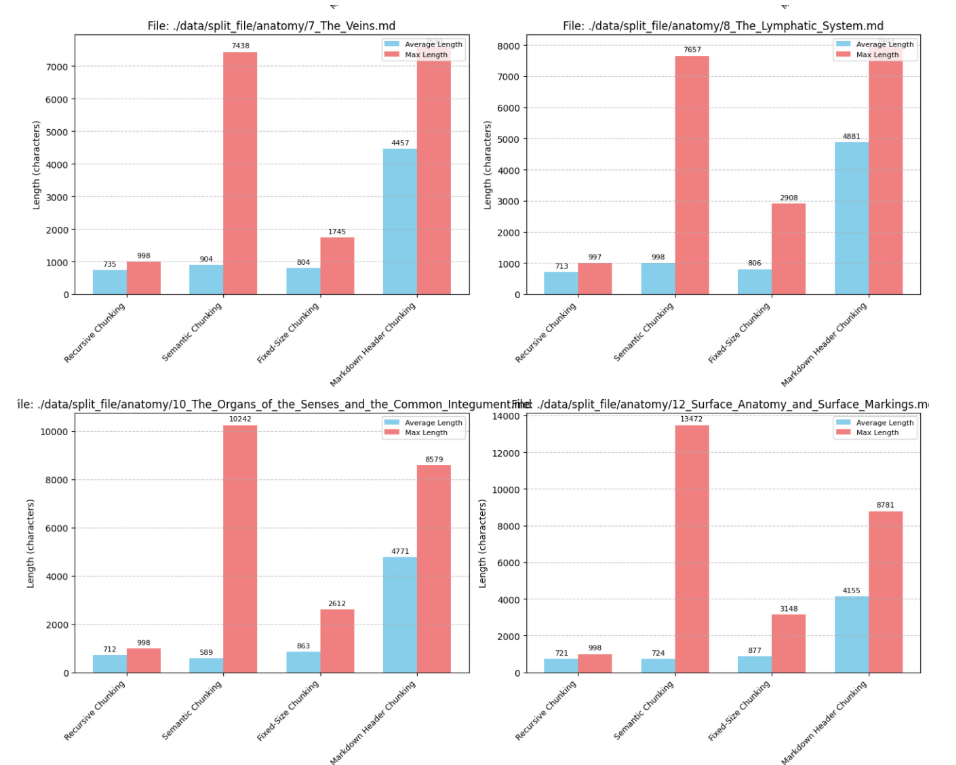
청킹 전략 비교
- 청킹 전략
- 재귀적 청킹 : 구분자를 사용하여 텍스트를 재귀적으로 분할(RecursiveCharacterTextSplitter)
- 시맨틱 청킹 : 임베딩 유사도 등을 활용하여 관련 있는 문장끼리 묶음(SentenceTransformer)
- 고정 크기 청킹 : 고정된 문자 수, 토큰 수를 기준으로 묶음(CharacterTextSplitter)
- 마크다운 헤더 청킹 : 헤더에 포함된 내용을 청크로 저장 & 헤더를 메타데이터에 저장
- 결과 비교
- 청크의 평균 길이 : 마크다운 » 재귀적 ≈ 시맨틱 ≈ 고정크기
- 청크의 최대 길이 : 시맨틱 ≈ 마크다운 » 고정크기 > 재귀적
- 해석
- 마크다운(814개 청크)
- 청크 개수가 가장 적고 청크의 크기가 압도적으로 길다
- 고려사항 : 청크 길이가 길어지면 LLM의 컨텍스트 윈도우 한계 초과할 수 있음
- 재귀적(5386개)
- 청크 개수가 가장 많고 최대 길이가 가장 짧다
- 정보를 세밀하게 검색
- 고려사항 : 관련 정보가 여러 청크에 분산될 수 있음
- 시맨틱 청킹(4856개)
- 평균 길이는 재귀/고정과 비슷하지만 최대 길이는 마크다운과 유사
- 의미적 연결을 찾아내 관련성 높은 정보 제공할 가능성 높음
- 고려사항 : 임베딩 모델 성능, 텍스트 특성에 따라 청킹 결과 달라짐
- 고정 크기 청크(4315개)
- 일관된 청크 크기 유지 → 컨텍스트 윈도우 관리 용이함
- 고려사항 : 의미적 경계 무시
- 마크다운(814개 청크)
W15
엔티티-관계 추출
문서에서 핵심 정보인 개체(Entity)와 관계(Relation)을 식별
- 문서 분할 : 원본 문서를 문단 단위로 분할
- 개체-관계 추출 : 각 문단에 대해 LLM을 활용해 개체와 관계 추출
- 엔티티-관계 정제 : 추출된 개체와 관계의 정확성 및 일관성을 높이기 위한 후처리
- 고유 식별자 할당 : “America”, “USA” 등 동일 대상을 지칭하는 표현을 하나의 개체로 매핑
- 표제어 : “is eating”, “ate” 등 동사 굴절 형태를 동사원형으로 정규화
- 관계 정의의 구체화/일반화 : 관계를 구체적, 또는 일반적으로 정의할지 결정
- 관계 경로 단순화 : 불필요하게 복잡한 경로를 단순화
지식 그래프 구축
- 수동 정제 작업 : 추출 및 정제 과정에서 발생할 수 있는 오류 최소화를 위한 수동 검수
- 그래프 DB 구축 : 정제된 JSON 파일을 기반으로 Neo4j AuroDB를 구축하여 저장
OCR
| 종류 | 특징 |
|---|---|
| Pytesseract | 저해상도/노이즈 이미지 및 복잡한 레이아웃에 어려움고해상도, 인쇄체에 적합필기체 텍스트 정확도 떨어짐 |
| PaddleOCR | 복잡한 배경 이미지에 높은 성능필기체 처리 가능 |
| TrOCR | Transformer 기반 모델인쇄체에 적합텍스트 내용, 크기, 스타일, 노이즈 및 회전변환에 따른 성능 저하 없음복잡한 문서 처리필기체 강점 |
| EasyOCR | 딥러닝 기반(CNN + LSTM, CTC) 라이브러리노이즈 이미지에서 Pytesseract보다 우수심한 블러, 낮은 해상도는 어려움필기체 처리 가능 |
| Keras-OCR | 노이즈, 회전, 왜곡된 텍스트 및 복잡한 배경에 강점 |
검색 로직
- 개체-관계 추출 및 분석
- LLM을 활용해 질문 분석
- 핵심 개체-관계 식별 및 추출
- Cypher 쿼리 동적 생성
- Neo4j에서 정보를 조회하기 위한 Cypher 쿼리를 동적으로 생성
- 개체들 간의 특정 관계 패턴을 명시하여 원하는 정보를 검색
- 지식 그래프 쿼리 실행
- Cypher 쿼리를 Neo4j AuraDB에 전송되어 실행
- 관련 정보 추출 및 정제
- 쿼리를 통해 찾아낸 개체를 통해 해당 개체가 존재하는 문단을 LLM에 입력
전체 프로세스
사용자 질문에 대해 지식 그래프에서 관련 정보 검색 및 답변 생성
- 초기화 : Neo4j AuraDB 데이터베이스에 연결하고 LLM 로더 초기화
- 개체-관계 추출 : 사용자 질문에서 개체-관계 추출
- Cypher 쿼리 생성 : 추출된 개체와 관계를 활용, 지식 그래프 검색에 필요한 Cypher 쿼리 생성
- Cypher 쿼리 실행 및 정보검색 : 생성된 Cypher 쿼리를 지식 그래프에서 실행
- 개체와 관계를 포함하는 사이퍼쿼리를 그래프에 전송
- 해당 쿼리에 맞는 원문 텍스트 정보를 가져옴
- 최종 답변 생성 : 검색된 관련 텍스트와 원본 질문을 바탕으로 최종 답변을 생성합니다
- 연결종료 : 모든 작업이 끝나면 close 메서드를 호출하여 데이터베이스 연결 종료
W16
OCR
유료 툴
| Google Cloud Document AI | Mistral OCR | Azure Document Intelligence | ABBYY FineReader | |
|---|---|---|---|---|
| 성능 | 93% | 94.89% | 80%이상? | 99.8% |
| 비용 | 1.5달러 1,000페이지https://cloud.google.com/vision/pricing?hl=ko | 1달러 1,000페이지https://mistral.ai/pricing#api-pricing | 1.5달러 1,000페이지https://azure.microsoft.com/en-us/pricing/details/ai-document-intelligence/ | 165$/년, 24$/월https://nurimall.co.kr/product/abbyy-finereader-pdf-corporate-3%EB%85%84-%EA%B8%B0%EC%97%85%EC%9A%A9-%EB%9D%BC%EC%9D%B4%EC%84%A0%EC%8A%A4-%ED%8C%8C%EC%9D%B8%EB%A6%AC%EB%8D%94/3677/ |
엔티티-관계 추출(LLMGraphTransformer)
KOS(지식 조직 시스템) 구축 프로세스
- 1차 추출
- 초기 스키마를 비워둔다
- LLMGraphTransformer()의 옵션 strict_mode=False 지정 → LLM이 무작위로 엔티티-관계 추출
- 문서에 포함된 엔티티-관계를 광범위하게 파악
- 1차 추출 결과 정제
- 1단계에서 생성된 결과물 분석
- 반복되거나 유사한 유형 통합, 의미 없는 유형 제거
- 스키마 초안 작성
- 반복 정제
- 스키마 초안 할당
- strict_mode=True 지정(정해진 스키마 내에서만 추출)
- 결과물 검토
- 누락된 엔티티/관계, 반복되는 엔티티/관계 등 스키마 정제
- 앞의 단계를 반복
검색 로직 고도화
- 그래프 탐색 + 유사도 검색
- 질문의 엔티티, 그래프의 엔티티를 비교 후, 정확하기 일치하는 엔티티를 찾음
- 정확하게 일치하지 않는다면, 벡터 유사도 검색을 통해 유사도가 임계치 이상인 엔티티 찾음
- 릴레이션도 위의 과정을 따른다
- 그래프 + 유사도 검색을 통해 얻어진 엔티티/관계가 포함되는 페이지, 문장을 찾음
- 찾은 문장의 전후로 n문장을 함께 LLM의 입력으로 넣는다→ 다른 방법 연구
- 질문의 엔티티, 그래프의 엔티티를 비교 후, 정확하기 일치하는 엔티티를 찾음
- KGE 모델 적용
- (주어, 술어, 목적어)형태의 triplet을 저차원의 벡터로 변환하는 역할
- 변환 기반 모델
- TransE : 기본 모델. 관계를 벡터 공간에서의 변환으로 모델링. 대칭 관계 표현에 한계
- TransR, TransD : TransE의 한계를 개산하기 위해 등장한 모델. 관계마다 다른 변환 행렬을 도입하여 엔티티-관계 상호작용 포착
- RotatE : 복소수 벡터 공간에서 관계를 회전으로 모델링. 대칭, 비대칭, 반전 관계를 효과적으로 표현
- 의미 매칭 기반 모델
- DistMult : 엔티티-관계를 벡터로 표현, 관계를 대각 행렬로 간주하여 점수 계산
- ComplEx : DistMult를 복소수 벡터 공간으로 확장하여 비대칭 관계 잘 모델링
- TuckER : 텐서 분해 기반 모델
- ConvE : 2D CNN을 사용하여 엔티티-관계 패턴 포착
출장 실험용 기성 데이터셋
- 해리포터 QA
- 해리포터 서사에 관한 질문-답변
- 마인크래프트 QA
- 마인크래프트 게임 세계관 기반
- 제작법, 몬스터 행동 양식 등 게임 고유의 논리적 규칙에 대한 질문-답변
출장 실험용 LLM 모델
- google/gemma-7b
- microsoft/Phi-mini-MoE-instruct
- Qwen/Qwen2.5-1.5B-Instruct
- UNIVA-Bllossom/DeepSeek-qwen-Bllossom-32B
해리포터 QA 데이터 답변 결과
- 구체적인 문맥이 주어지지 않으면 어떤 모델도 답변할 수 없는 데이터셋
<질문 1>
What can we infer about Mr. and Mrs. Dursley's attitude towards magic?
<답변>
The text does not provide information about Mr. and Mrs. Dursley's attitude towards magic, therefore I cannot answer this question.
<정답 답변>
From the passage, it appears that Mr. and Mrs. Dursley disapprove of and distance themselves from anything related to magic.
댓글남기기