4/16 NLP 이론
-
sigomid보다 ReLU를 많이 쓰는 이유
-
계산량이 적다. .
sigmoid함수는 분모에 지수함수($e^{-x}$)가 있고 ReLU함수는 서로다른 선형함수(y = 0, y = x)가 결합된 비선형함수로 이루어져있어 계산량이 ReLU함수가 더 적다.
-
기울기소실 문제
sigmoid함수는 x의 절댓값이 커지면(매우 큰 양수 또는 매우 작은 음수) 기울기가 0에 수렴하므로 역전파시 더이상 학습이 되지 않는 기울기소실문제가 발생한다. ReLU함수는 x가 음수인 경우에 마찬가지로 기울기가 0이 되므로 이를 해결하기 위해 ReLU함수에서 파생된 Leaky ReLU, parametric ReLU, exponential ReLU함수를 사용한다.
-
-
Non linearity라는 말의 의미와 그 필요성은?
비선형성 이라는 의미로 선형적이지 않다는 의미이다. 선형성은 x가 증가하거나 감소하면 x의 변화량에 비례해서 y도 변화한다는 의미이다. 즉 선형성은 예측가능하게 움직인다는 의미이며 비선형성은 예측가능하지 않게 움직인다는 의미이다. 비선형성의 필요성은 모델을 학습할 때 일상생활에서 예측가능하지 않은 복잡한 패턴을 학습할 때 활성화함수로 비선형함수를 사용한다. layer 3개에 대해서 활성화함수를 y = ax(a : constant)와 같은 선형함수를 사용한다고 하면 y = a(a(ax))가 되며 $a^{3}$는 또다른 상수로 치환이 가능하게 되므로 layer를 여러개 쌓은 의미가 없어진다.
-
ReLU의 문제점은?
sigmoid보다 ReLU를 많이 쓰는 이유는? 질문 참고
-
ReLU로 어떻게 곡선 함수를 근사하나?
하나의 은닉층을 가지는 인공신경망은 임의의 연속인 다변수 함수를 원하는 정도의 정확도로 근사할 수 있음을 말하는 보편근사정리에 의해서 ReLU함수는 곡선함수를 근사할 수 있다.
-
gradient descent에 대해서 쉽게 설명한다면?
목적함수에 대해서 global minimum을 찾는 최적화 기법으로 임의의 지점에서 시작해서 그 지점의 기울기가 음수라면 왼쪽, 양수라면 오른쪽으로 이동하며 최적해를 찾는 기법이다.
-
왜 꼭 gradient를 써야할까?
global minimum은 y값이 작아지는 방향으로 이동해야 하기 때문에 기울기를 기반으로 방향을 찾는다.
-
그 그래프에서 가로축과 세로축은 각각 무엇인가?
가로축은 파라미터, 세로축은 loss를 의미한다.
-
실제 상황에서는 그 그래프가 어떻게 그려질까?
local minimum이 매우 많거나 saddle point가 생기는 고차원 함수로 그려질 가능성이 높다.
-
GD중에 때떄로 loss가 증가하는 이유는?
x값을 이동하는 폭을 결정하는 학습률이 너무 작으면 local minimum에 도달할 확률이 높고 학습률이 너무 높으면 최적해에 도달하지 못하고 계속 발산하게 된다.
-
back propagation에 대해서 쉽게 설명한다면?
신경망의 마지막에 계산된 loss를 다시 거꾸로 전달해서 그 loss를 기반으로 loss값이 작아지는 방향으로 은닉층의 가중치 값들을 수정해서 최적화하는 방법이다.
-
local minima 문제에도 불구하고 딥러닝이 잘되는 이유는?
실제 task에서는 변수의 개수가 많아져 목적함수의 차원이 매우 높아진다. 이러한 고차원 목적함수가 local minimum에 빠지기 위해서는 모든 변수가 local minimum에 빠져야 하므로 큰 문제가 되지 않는다.
-
GD가 local minima문제를 피하는 방법은?
문제 상황에 맞는 optimizer를 사용한다.
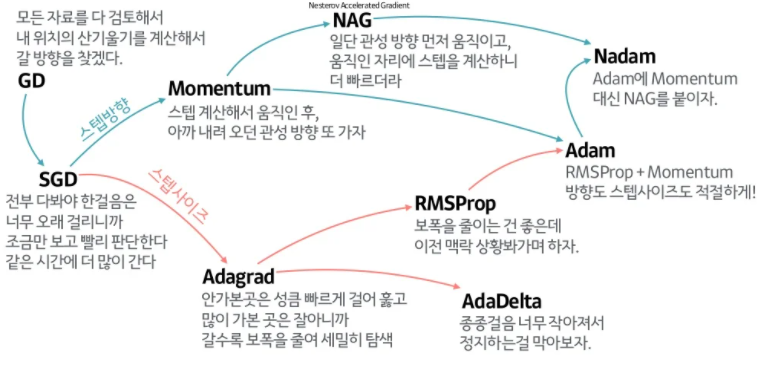
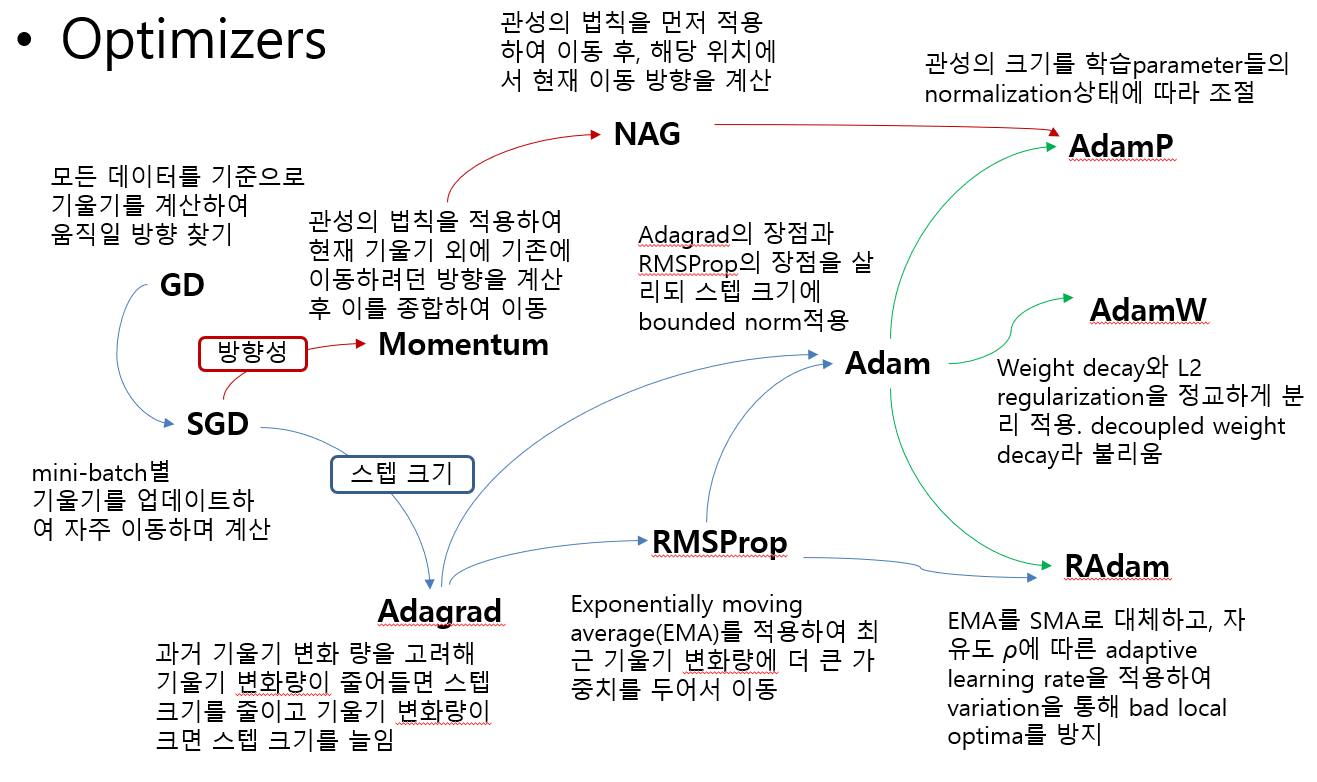
-
찾은 해가 global minimum인지 알 수 있는 방법은?
global minimum인지 정확히 알 수 있는 방법은 없지만 test 데이터의 성능을 평가해 봄으로써 global minimum에 가까운지 평가할 수 있다.
-
토큰화(tokenization)
토큰화는 언어를 의미를 가지는 최소 단위의 문자열로 쪼개는 과정이다. 토큰의 단위는 하고자 하는 task에 따라 다르게 정의할 수 있다. 토큰화 도구마다 결과가 모두 다르다.
-
어간 추출 & 표제어 추출
-
표제어 추출
표제어 추출은 단어 의미를 가진 가장 작은 단위로 쪼개는 행위이로 기본 사전형 단어로 만든다고 생각하면 된다. 예를 들어, am, are, is의 표제어는 be이다.
-
어간 추출
어간 추출은 정해진 규칙을 기반으로 단어의 어미를 자르는 작업이다. 예를 들어, was의 표제어는 be이지만 was를 PorterStemmer()을 이용해 어간 추출 한다면 결과는 wa가 된다. 포터 알고리즘의 어간추출은 ALIZE => AL, ANCE => 제거, ICAL => IC로 만드는 등 의미와 상관없이 규칙만으로 단어를 변형하게 되어 사전에 존재하지 않는 단어가 나올수도 있다.
-
-
불용어
불용어는 자주 등장하지만 큰 의미를 가지지 않으며 학습 결과에 유의미한 영향을 미치지 않는 쓸모 없는 단어를 의미한다(I, me, my, 조사 등).
-
임베딩
자연어 처리에서 단어를 컴퓨터가 이해할 수 있는 숫자로 이루어진 벡터로 매핑해주는 작업이다. 0과 1로 이루어진 벡터로 변환하는 원핫 인코딩, 실수로 이루어진 벡터로 변환하는 워드 임베딩 방식이 있다. 원핫 벡터는 1로 단어가 속한 클래스를 표현하기 때문에 벡터의 차원이 높고 임베딩 벡터는 차원이 낮아진다. 그리고 원핫 벡터로 단어를 표현하면 단어간의 유사도를 측정할 수 없지만 임베딩 벡터는 유사도를 측정할 수 있다.
-
word2vec vs FFNN
-
word2vec : 중심단어 예측 vs FFNN : 다음단어 예측(언어모델링)
-
구조

-
속도
word2vec은 은닉층을 제거와 네거티브 샘플링 덕분에 FFNN에 비해 속도가 빨라졌다.
-
-
네거티브 샘플링
word2vec에서 단어의 수가 늘어날수록 모든 단어의 임베딩벡터를 업데이트 하는 것은 비효율적이다.
네거티브 샘플링은 중심단어, 주변단어가 윈도우 내에 존재하는 이웃관계인지에 대한 확률을 예측한다. 아래 그림과 같이 윈도우 내에 존재하는 단어들은 레이블1, 아닌 단어들을 레이블 0으로 분류한다.


왼쪽 임베딩 테이블은 입력1, 오른쪽 테이블은 입력2에 대한 임베딩 테이블이다.

그 후 중심단어와 주변단어의 내적값을 계산해 레이블과의 오차를 최소화하는 방향으로 임베딩 벡터를 업데이트 한다.
-
CBoW
주변단어를 바탕으로 중심단어를 예측하는 word2vec 기법
-
Skip-gram
중심단어를 바탕으로 주변단어를 예측하는 word2vec 기법. 보통 skip-gram방식의 성능이 높다.
-
FastText
fastText와 word2vec의 차이점은 word2vec은 단어를 최소의 단위로 취급하지만 fastText는 subword를 고려하여 학습한다는 점이다.
예를 들어, apple의 경우 다음과 같이 6개의 subword로 쪼개진다는 것이다.
# n = 3인 경우 <ap, app, ppl, ple, le>, <apple>fastText의 장점은 다음과 같다.
-
OOV
이전에 birth와 place라는 단어가 등장해 학습을 했다고 가정하면 새로운 birthplace라는 단어가 등장했을 때 다른 단어와의 유사도를 계산할 수 있다는 점이다(word2vec은 불가능).
-
빈도수가 적은 단어
희귀한 단어 또는 오타가 난다면 word2vec에서는 학습이 제대로 되지 않지만 fastText에서는 일정수준 학습이 가능하다.
예를 들어 apple과 오타가 난 appple의 경우 겹치는 n-gram을 가지므로 오타를 어느정도 커버할 수 있다.
-
-
GloVe
-
LSA
-
LDA
-
LSTM
-
ELMo
댓글남기기