12/22 [논문 해석] Learning Phrase Representation using RNN Encoder-Decoder for Statistical Machine Translation
이 포스팅은 논문 Learning Phrase Representation using RNN Encoder-Decoder for Statistical Machine Translation를 읽고 해석한 글입니다. .
Learning Phrase Representation using RNN Encoder-Decoder for Statistical Machine Translation(Kyunghyun Cho)
Abstract
이 논문에서 우리는 두개의 RNN으로 구성되어있는 RNN 인코더-디코더라는 새로운 신경망 모델을 제안한다. 하나의 RNN은 일련의 단어들을 고정된 길이의 벡터 표현으로 인코딩하고 다른 RNN은 이 벡터표현을 다른 일련의 단어들로 디코딩한다. 제안된 모델의 인코더와 디코더는 소스 시퀀스가 주어지면 타켓 시퀀스의 조건부 확률을 최대화하기 위해 함께 훈련된다. 통계젹 기계 번역 시스템의 성능이 RNN 인코더 디코더에서 계산된 구문 쌍의 조건부 확률을 기존 로그 선형모델의 추가 기능으로 사용함으로 경험적으로 향상된 것으로 발견된다. 정성적으로 우리는 제안된 모델이 언어 구문의 의미적으로, 구문적으로 의미있는 표현을 학습하는것을 알 수 있다.
1. Introduction
심층 신경망은 객체 인식, 음성 인식과 같은 다양한 적용에서 훌륭한 성공을 보여줬다. 게다가 많은 최근의 연구는 신경망이 자연어처리의 많은 작업에 성공적으로 사용될 수 있음을 보여줬다. 이는 언어 모델링, paraphrase 감지, 단어 임베딩 추출을 포함한다. 통계적 기계 번역(SMT) 분야에서 심층신경망은 유망한 결과를 내놓기 시작했다. (Schwenk, 2012) 는 구문 기반의 SMT시스템의 프레임워크의 피드포워드 신경망의 성공적인 사용을 요약한다.
SMT에 신경망을 사용하는 연구를 따라 이 논문은 관습적인 구문 기반 SMT 시스템의 일부로 사용될 수 있는 새로운 신경망 아키텍처에 집중한다. 우리가 앞으로 RNN 인코더-디코더라고 부를 제안된 신경망 아키텍처는 인코더와 디코더 쌍으로 역할을 하는 두개의 RNN으로 구성되어있다. 인코더는 가변길이 소스 시퀀스를 고정 길이 벡터로 매핑하고 디코더는 벡터 표현을 가변 길이 타겟 시퀀스로 돌려놓는다. 두 신경망(RNN)은 소스 시퀀스가 주어지면 타겟 시퀀스의 조건부 확률을 최대화하기 위해 함께 훈련된다. 게다가 우리는 메모리 용량과 훈련의 용이성 모두를 향상하기 위해 더 정교한 은닉 유닛을 사용할 것을 제안한다.
새로운 은닉 유닛을 가진 제안된 RNN 인코더 디코더는 영어에서 프랑스어로 번역하는 작업에서 경험적으로 평가된다. 우리는 영어 구문에서 일치하는 프랑스 구문으로 번역될 확률을 학습하기 위해 모델을 훈련한다. 모델은 각 구문테이블에 있는 구문쌍에 점수를 메김으로써 표준 구문기반 SMT 시스템의 일부로써 사용된다. 경험적 평가는 RNN 인코더 디코더로 구문 쌍을 점수메기는 이러한 접근법이 번역 성능을 향상시킴을 밝혔다.
우리는 기존의 번역 모델의 구문 점수를 비교해서 훈련된 RNN 인코더-디코더를 정성적으로 분석한다. 정성적 분석은 RNN 인코더 디코더는 구문 테이블에 있는 언어 규칙성을 더 잘 포착함을 보여주고 간접적으로 전체 번역 성능의 정성적 향상을 더 잘 설명한다. 추가적인 모델의 분석은 RNN 인코더-디코더가가 구문의 의미론적 구문론적 구조가 보존된 구문의 연속적인 공간 표현을 학습한다는 것을 밝혔다.
2 RNN Encoder-Decoder
2.1 Preliminary : Recurrent Neural Network
RNN은 은닉층 h와 가변길이 시퀀스 x = (x1, … , xT)에서 연산되는 출력 y로 구성된 신경망이다. 각 시점 t에서 rnn의 은닉층 $h_t$는 다음과 같이 업데이트된다.
식(1)
\[h_{t} = f(h_{t-1},\ x_t)\]f는 비선형 활성화 함수이다. f는 원소별 로지스틱 시그모이드 함수처럼 단순할수도 있고 LSTM 유닛처럼 복잡할 수도 있다.
RNN은 시퀀스의 다음 단어를 예측하도록 훈련되어 시퀀스의 확률 분포를 학습할 수 있다. 이러한 경우에 각 시점 t에서 출력은 조건부 분포 $p(x_{t}|x_{t-1},…,x_{1})$이다. 예를 들어 다항분포(1-of-K coding == 원핫인코딩)는 소프트맥스 함수를 사용하여 출력할 수 있다.
식(2)
\[p(x_{t,j} = 1 | x_{t - 1},\ ... \ ,x_{1}) = \frac{exp(w_{j}h_{t})}{\sum_{j'=1}^{K}exp(w_{j'}h_{t})}\]j = 1, … ,K에서 $w_{j}$는 가중치 행렬 W의 행이다. 이 확률들을 결합하면 우리는 시퀀스 x의 확률을 계산할 수 있다.
식(3)
\[p(x) = \prod_{t = 1}^{T}p(x_{t}|x_{t-1},\ ...\ , x_{1})\]이러한 학습된 분포에서 매 시점마다 기호를 반복적으로 샘플링하여 새로운 시퀀스를 샘플링하는 것은 간단하다.
2.2 RNN Encoder-Decoder
이 논문에서 가변길이 시퀀스를 고정길이 벡터표현으로 인코딩하고 주어진 고정길이 벡터표현을 가변길이 시퀀스로 디코딩하기 위해 학습하는 새로운 신경망 아키텍처를 제안한다. 확률적인 관점에서 이 새로운 모델은 가변길이 시퀀스에 다른 가변 길이 시퀀스가 조건으로 걸려있는 조건부 분포를 학습하기 위한 일반적인 방법이다. 예를 들면 $p(y_{1},…,y_{T’}|x_{1}, … ,x_{T})$에서 입력과 출력 시퀀스의 길이 T와 T’이 다르다는 것을 알아야 한다.
인코더는 입력 시퀀스 x의 단어를 순차적으로 읽는 RNN이다. 인코더가 각 단어를 읽음에 따라 RNN의 은닉층이 식(1)에 따라 변한다. 시퀀스의 끝(end of sequence 표시가 되어있는)을 읽은 후 RNN의 은닉층은 전체 입력 시퀀스의 요약 c이다.
제안된 모델의 디코더는 은닉층 $h_{t}$가 주어진 다음 단어 $y_{t}$를 예측해서 출력 시퀀스를 생성하도록 훈련되는 RNN이다. 하지만 Section 2.1에서 설명된 RNN과는 다르게 $y_{t}$와 $h_{t}$ 모두 입력 시퀀스의 요약 c가 조건으로 걸려있다. 이런 이유로 시점 t의 디코더의 은닉층은 다음과 같이 계산된다.
\[h_{t} = f(h_{t-1},y_{t-1},c)\]그리고 유사하게 다음 단어의 조건 분포는 다음과 같다.
\[P(y_{t}|y_{t-1}, y_{t-2},...,y_{1},c) = g(h_{t},y_{t-1},c)\]f와 g는 주어진 활성화 함수이다(g는 유효한 확률을 만들어내야 한다. 예를 들면 소프트맥스 함수).
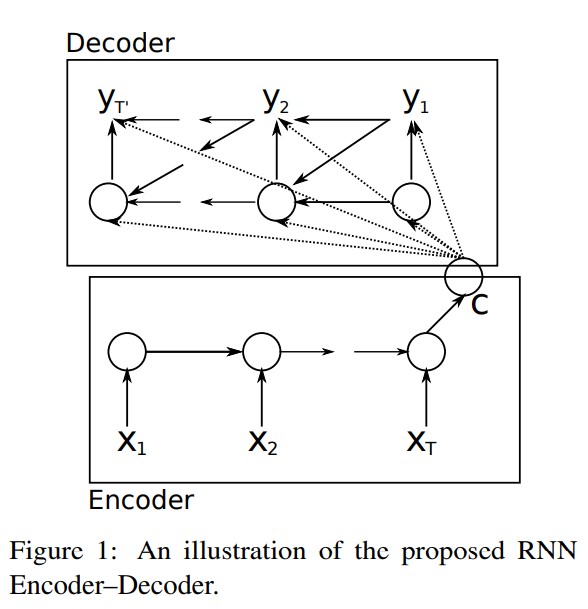
그림 1은 제안된 모델 아키텍처의 그림 설명이다.
제안된 RNN 인코더 디코더의 두개의 구성요소는 조건부 로그 가능도를 최대화하도록 훈련된다.
식(4)
\[max_{\theta}\frac{1}{N}\sum_{n=1}^{N}log\ p_{\theta}(y_{n}|x_{n})\]$\theta$는 모델 파라미터의 집합이고 각 (xn, yn)은 훈련 데이터셋의 (입력 시퀀스, 출력 시퀀스) 쌍이다. 우리의 경우에는 입력으로 시작된 디코더의 출력이 미분가능하기 때문에 우리는 모델 파라미터를 추정하기 위해 그래디언트 기반의 알고리즘을 사용할 수 있다.
RNN 인코더-디코더가 훈련됨에 따라 모델은 두가지 방향으로 사용될 수 있다. 한가지는 입력 시퀀스가 주어졌을 때 타겟 시퀀스를 생성하는 것이다. 한편 모델은 입력과 출력 시퀀스 쌍으로 주어졌을 때 점수를 메기는데 사용될 수도 있다. 점수는 단순히 식(3), 식(4)로부터 나온 확률 $p_{\theta}(y|x)$이다.
2.3 Hidden Unit that Adaptively Remembers and Forgets
새로운 모델 아키텍처와 더불어 우리는 LSTM에 영감을 받았지만 계산하고 구현하기는 훨씬 단순한 새로운 은닉 유닛을 제안한다. 그림 2는 제안된 은닉 유닛의 그림 설명이다.
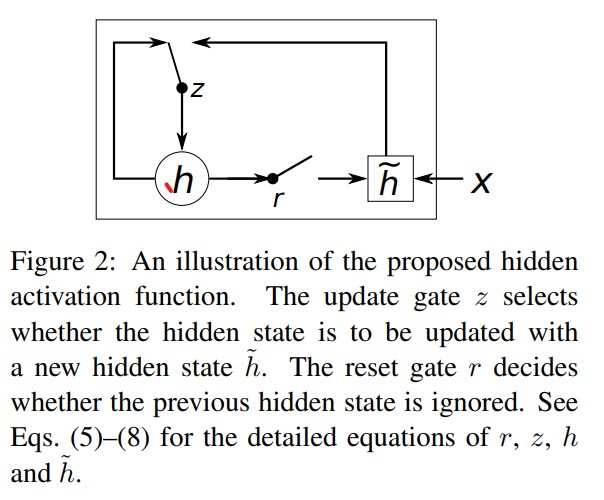
j번째 은닉 유닛의 활성화가 어떻게 계산되는가 살펴보자. 첫번째로 reset 게이트 rj는 다음과 같이 계산된다.
\[r_{j} = \sigma([W_{r}x]_{j}\ +\ [U_{r}h_{t-1}]_{j})\]$\sigma$는 시그모이드 함수, $[.]{j}$는벡터의 j번째 원소를 의미한다. x와 $h_{t-1}$ 는 각각 입력과 이전 은닉층을 의미한다. $W_r$ 과 $U{r}$은 학습되어진 가중치 행렬이다.
유사하게 update 게이트 $z_{j}$는 다음과 같이 계산된다.
\[z_{j} = \sigma([W_{z}x]_{j}\ +\ [U_{z}h_{t-1}]_{j})\]제안된 유닛 $h_{j}$의 실제 활성화는 다음과 같이 계산된다.
식(7), (8)
\(h_{j}^{t} = z_{j}^{t-1}\ +\ (1-z_{j})H_{j}^{t}\\\ H_{j}^{t}=\phi([Wx]_{j} + [U(r\ *\ h_{t-1})]_{j})\) (식(7)에서 곱셈 *는 원소별 곱을 의미하는 Hadamard product이다.)
이 공식에서 reset 게이트가 0에 가까워지면 은닉층은 강제로 이전 은닉층을 무시하게 되고 현재 입력으로만 리셋하게 된다. 이는 은닉층이 나중에 관련이 없다고 판단되는 어떤 정보든 버릴수 있게 한다. 따라서 더 compact한 표현이 가능해진다.
한편 update 게이트는 이전 은닉층을 현재 은닉층으로 전달되는 정도를 통제한다. 이는 LSTM 네트워크의 메모리 셀과 비슷하게 행동하고 RNN이 장기 정보를 기억하도록 도와준다. 게다가 이눈 leaky integration unit의 적응형 변형으로 간주될 수 있다.
각 은닉층이 별도의 reset, update 게이트를 가지고 있으므로 각 은닉 유닛은 다양 시간 범위에 따른 의존성을 포착하는 것을 학습할 수 있다. 단기 의존성을 캡쳐하는 것을 학습한 유닛은 active한 reset 게이트를 가지는 경향이 있지만 장기 의존성을 캡쳐하는 reset 게이트는 더 active한 update 게이트를 가질 것이다.
우리의 예비 실험에서 이 새로운 유닛을 gating 유닛들과 함께 사용하는 것이 중요한것을 발견했다. 우리는 gating이 없는 자주 사용되는 tanh 유닛으로는 의미있는 결과를 얻을 수 없다.
3 Statistical Machine Translation
흔히 사용되는 통계적 기계 번역 시스템에서 시스템의 목표(특히 디코더)는 다음 식을 최소화하는 문장 e가 주어졌을 때 번역 f를 찾는 것이다.
\[p(f|e)\propto p(e|f)p(f)\]우변의 첫번째 항은 translation model, 두번째 항은 language mode라고 한다. 하지만 실제로는 대부분의 SMT 시스템들은 log p(f|e)를 추가 feature과 다음의 가중치를 가진 로그 선형모델로써 모델링한다.
식 (9)
\[log\ p(f|e) = \sum_{n=1}^{N}w_{n}f_{n}(f,\ e)\ + \ log\ Z(e)\]$f_{n}$와 $w_{n}$은 n번째 feature, weight이다. Z(e)는 가중치에 의존하지 않는 정규화 상수이다. 가중치들은 development set(검증용 데이터)에서 BLEU 점수를 최대화하도록 최적화된다.
구문 기반 SMT 프레임워크에서 번역 모델 log p(e|f)는 source 문장, target 문장에서 일치하는 구문들의 번역 확률로 인수분해된다. 이 확률들은 로그 선형 모델의 추가적인 feature을 고려하고 BLEU 점수를 최대화에 따라 가중치를 부여한다.
신경망 언어 모델은 (Bengio at el., 2003)에서 제안된 이래로 신경망은 SMT 시스템에서 널리 사용된다. 많은 경우에 신경망들은 번역 가설(n-best lists)(Schwenk at el., 2006)을 점수를 다시 매기기위해 사용된다. 하지만 최근에 번역된 소스 문장의 표현을 추가적인 입력으로 사용하는 문장에 점수를 메기기 위해 신경망을 훈련시키는 것에 흥미가 생겼다.
3.1 Scoring Phrase Pairs with RNN Encoder-Decoder
여기 우리는 구문 쌍의 테이블에서 RNN 인코더-디코더를 훈련시키고 SMT 디코더를 튜닝할 때 이것의 점수를 식(9)의 로그 선형 모델의 추가적인 feature로써 사용한다.
RNN 인코더-디코더를 훈련할 때 우리는 원본 말뭉치에 잇는 각 구문 쌍의 (정규화된) 빈도들을 무시한다. 이 방법은 첫째로 정규화된 빈도에 따라 큰 구문 테이블에서 구문 쌍을 무작위로 선택하는 계산 비용을 감소하기 위해서이고, 둘째로 RNN 인코더-디코더가 단순히 구문쌍의 발생 횟수에 따라 구문쌍의 순위를 매기도록 학습되지 않도록 보장하기 위해 취해진다. 이 선택의 하나의 근본적인 이유는 현재 구문테이블의 번역 확률은 이미 원본 말뭉치의 구문쌍의 빈도를 반영하기 때문이다. 일정한 용량을 가진 RNN 인코더-디코더를 사용하여 이 모델의 대부분의 용량이 언어적 규칙을 학습하는데 집중되도록 하려고 노력한다. 즉 적절한 그리고 부적절한 번역을 구별, 또는 적절한 번역의 “다양체(manifold)”를 학습하는데 집중하도록 한다.
RNN 인코더-디코더가 훈련되면 현재 구문 테이블에 각 구문쌍의 새로운 점수를 추가한다. 이는 새로운 점수들이 계산 시 추가 오버헤드를 최소화하는 현재 튜닝 알고리즘에 입력되도록 한다.
Schwenk가 (Schwenk, 2012)에서 말한것처럼 제안된 RNN 인코더-디코더로 현재 구문 테이블을 완전히 대체하는 것이 가능하다. 이러한 경우에 주어진 소스 구문에 대해서 RNN 인코더-디코더는 (좋은) 타겟 구문의 목록을 생성한다. 하지만 이를 위해서는 반복적으로 수행되어야 하는 값비싼(복잡한)샘플링 절차가 필요하다. 따라서 이 논문에서 우리는 구문 테이블의 구문 쌍들의 점수를 다시 메기는것만 고려한다.
3.2 Related Approaches : Neural Networks in Machine Translation
경험적인 결과를 보여주기 전에 우리는 SMT의 맥락에서의 신경망을 사용하기 위해 제안된 최근의 많은 연구들을 얘기해보자.
(Schwenk, 2012)에서 Schwenk는 구문쌍 채점의 유사한 접근법을 제안했다. RNN기반 신경망 대신에 그는 고정길이 입력(7단어, 0패딩)과 고정길이 출력(7단어)을 가진 피드포워드 신경망을 사용했다. 채점을 위해 특별히 사용되는 경우 SMT 시스템의 구문, 최대 구문 길이는 종종 작게 선택된다. 하지만 구문의 길이가 증가하거나 다른 가변길이 시퀀스 데이터에 신경망을 적용함에 따라 신경망이 가변길이 입.출력을 다룰 수 있는 것이 중요하다. 제안된 RNN 인코더-디코더는 이러한 적용에 잘 맞다.
(Schwenk, 2012)와 유사하게 (Devlin et al, 2014)가 번역 모델을 모델링하기 위해 피드포워드 신경망을 사용하는 것을 제안했다. 하지만 한번에 타겟 구문에서 하나의 단어를 예측한다. 그들은 인상적인 향상을 보고했지만 그들의 접근법은 여전히 입력구문(또는 문맥 단어)의 최대 길이가 선험적으로 고정되어야 한다.
비록 이것이 정확히 그들이 훈련한 신경망이 아닐지라도 (Zou et al, 2013)의 저자들은 단어/구문의 bilingual 임베딩을 학습할 것을 제안했다. 그들은 SMT 시스템의 구문쌍의 추가적인 점수로 사용되는 구문들의 쌍 사이의 거리를 계산하기 위해 학습된 임베딩을 사용했다.
(Chandar et al, 2014)에서 피드포워드 신경망을 입력 구문의 bag-of-words 표현에서 출력 구문으로의 맵핑을 학습하기 위해 훈련했다. 이는 구문의 입력 표현이 bag-of-words라는 점을 제외하면 제안된 RNN 인코더-디코더와 (Schwenk, 2012)에 제안된 모델 모두와 밀접한 관련이 있다. BoW 표현과 유사한 접근법은 (Gao et al, 2013)에서 제안되었다. 먼저 두개의 RNN을 사용한 유사한 인코더-디코더 모델은 (Socher et al, 2011)에서 제안되었지만 그들의 모델은 한개의 언어 세팅으로 제한되었다. 즉 모델은 입력 문장을 재구성한다. 더 최근에는 다른 RNN을 사용하는 인코더-디코더 모델은 (Auli et al, 2013)에서 제안되었고 여기서 디코더는 소스 문장 또는 소스 컨텍스트의 표현에 따라 조건이 지정된다.
RNN 인코더-디코더와 (Zou et al, 2013)의 접근법 사이의 중요한 차이점은 소스의 단어들의 순서와 타겟 구문들이 고려된다는 것이다. RNN 인코더-디코더는 자연스럽게 같은 단어를 가지지만 순서가 다른 시퀀스들을 구분하는 반면 앞서 언급한 접근법은 순서 정보를 실질적으로 무시한다.
RNN 인코더-디코더와 연관된 가장 밀접한 접근법은 (Kalchbrenner and Blunsom, 2013)에서 제안된 Recurrent Continuous Translation Model(Model2)이다. 이 논문에서 인코더와 디코더로 구성된 유사한 모델을 제안한다. 우리 모델과 차이점은 그들은 인코더에 convolutional n-gram model(CGM)을 사용하고 inverse CGM의 혼합 그리고 RNN을 디코더에 사용한다. 하지만 그들은 관습적인 SMT 시스템에서 제안된 n-best list를 재채점하고 gold standard 번역의 perplexity를 계산함으로써 그들의 모델을 평가했다.
4. Experiments
우리는 WMT’14 워크숍의 영어/프랑스어 번역 작업으로 우리의 접근법을 평가한다.
4.1 Data and Baseline System
많은 양의 리소스들은 WMT’14 번역 작업의 프레임워크에서 영어/불어 SMT 시스템을 만들 수 있다. 2개언어 말뭉치는 Europarl(61M개 단어), news commentary(5.5M), UN(421M), 그리고 두개의 크롤링된 말뭉치 각각 90M, 780M개의 단어를 포함한다. 마지막 두개의 말뭉치들은 다소 노이즈가 있다. 불어 모델을 훈련시키기 위해 bitext의 target side 외에도 크롤링된 신문 자료의 약 712M개의 단어를 사용할 수 있다. 모든 단어 개수는 토큰화 이후 불어 단어를 나타낸다.
이러한 모든 데이터를 연결하여 통계적 모델들을 훈련하는 것이 최적의 성능이 나오는 것은 아니며 다루기 힘든 극도로 큰 모델이 생성된다는 것은 일반적으로 인정된다. 대신에 주어진 업무에서 데이터의 가장 연관있는 하위집합에 집중해야 한다. 우리는 (Moore and Lewis, 2010)에서 제안된 데이터 선택 방법과 이를 이중텍스트(bitext)로 확장한 방법(Axelrod et al, 2011)을 적용하여 이를 수행했다. 이와 같은 방법으로 우리는 언어 모델링을 하기 위해 2G개의 단어에서 418M개의 하위집합을 선택하고 RNN 인코더-디코더 학습을 위해 850M개의 단어에서 348M개의 하위집합을 선택했다. 우리는 MERT의 데이터 선택과 가중치 튜닝을 위한 테스트 데이터 newstest2012 and 2013을 사용했고 newstest2014를 우리의 테스트 데이터로 사용했다. 각 데이터는 7만개 이상의 단어와 단일 참조 번역이 있다.
제안된 RNN 인코더-디코더를 포함한 신경망을 훈련하기 위해 우리는 소스 단어와 타겟 단어를 영어와 불어 모두에서 가장 자주 등장하는 15,000개의 단어로 제한한다. 이는 약 93%의 데이터를 커버한다. 단어에 속하지 않는 단어들은 특별 기호 [UNK]로 지정한다.
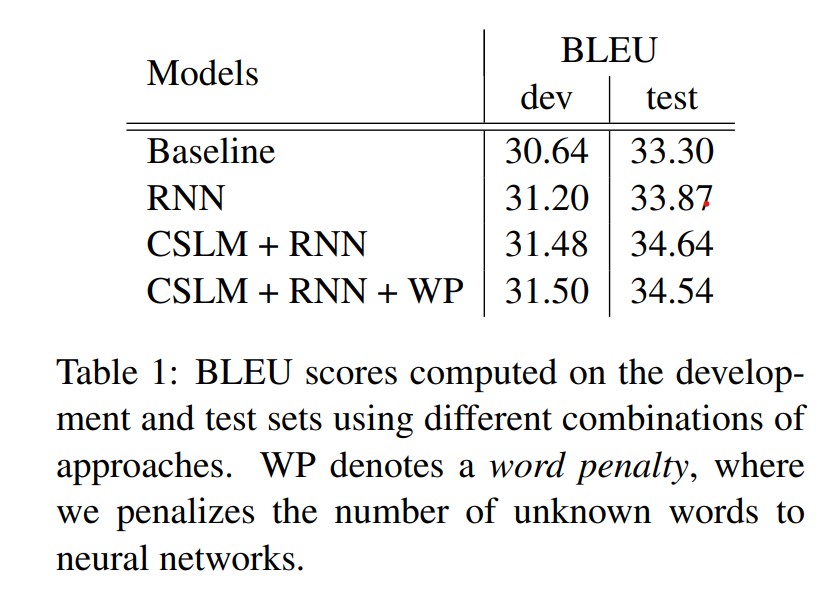
베이스라인 구문 기반 SMT 시스템은 기본 설정으로 Moses를 사용하여 구축되었다. 이 시스템은 각각 검증용 데이터와 테스트 데이터에서 BLEU 점수 30.64, 33.3점을 달성했다.
4.1.1 RNN Encoder-Decoder
실험에 사용된 RNN 인코더-디코더는 인코더와 디코더에서 제안된 게이트를 가진 1,000개의 은닉 유닛들을 가진다. 각 입력 기호 $x_{t}$와 은닉 유닛은 두개의 저차원 행렬로 근사되고 출력 행렬도 유사하게 근사된다. 우리는 각 단어에 대해 100차원의 임베딩을 학습하는것과 동일 100차원 행렬을 사용한다. 식(8)에서 H에 사용되는 활성화 함수는 tanh 함수이다. 디코더의 은닉층으로부터 출력층까지의 계산은 각각 2개의 입력을 풀링하는 500개의 최대 출력 유닛을 갖는 단일 중간 계층이 있는 심층 신경망으로 구현된다.
RNN 인코더-디코더의 recurrent 가중치 파라미터를 제외한 모든 가중치 파라미터들은 0평균 분산이 0.01인 등방성 가우스 분포로부터 샘플링되어 초기화된다. recurrent 가중치 행렬의 경우 먼저 white Gaussian 분포에서 샘플링하고 왼쪽 특이값 벡터 행렬을 사용했다.
우리는 하이퍼 파라미터 $\epsilon = 10^{-6}$ 와 $\rho = 0.95$를 가지는 RNN 인코더-디코더를 훈련하기 위해 Adadelta와 SGD를 사용했다. 각 업데이트에서 우리는 구문 테이블로부터의 64개의 무작위 선택된 구문 쌍을 사용한다. 모델은 대략 3일동안 훈련되었다.
실험에서 사용된 아키텍처의 디테일은 보충 자료에 더 깊이있게 설명했다.
4.1.2 Neural Language Model
제안된 RNN 인코더-디코더의 구문쌍 채점의 효율성을 평가하기 위해 우리는 또한 타겟 언어 모델(CSLM) (Schwenk, 2007) 학습을 위한 신경망 사용의 관습적인 접근법 또한 시도했다. 특히 CSLM을 사용한 SMT 시스템과 RNN 인코더-디코더로 제안된 구문 채점 접근법을 사용하는 시스템을 비교하면 SMT 시스템의 여러 부분에 있는 다중 신경망의 기여가 합산되거나 중복되는지 여부가 명확해진다.
우리는 타겟 말뭉치로부터 7gram의 CSLM 모델을 훈련했다. 각 입력단어는 임베딩 공간 $R^{512}$로 사영되었고 연결되어 3072차원 벡터를 형성했다. 연결된 벡터는 두개의 정류된 층(사이즈가 각각 1536, 1024)을 통해 입력되었다. 출력층은 simple 소프트맥스 층이다(식(2)). 모든 가중치 파라미터들은 -0.01, 0.01 사이의 균등분포로 초기화되었고 모델은 10 에폭동안 검증 perplexity가 향상되지 않을 때까지 훈련되었다. 훈련이 끝난 후 언어 모델은 perplexity 45.80을 달성했다. 검증 데이터셋은 말뭉치의 랜덤으로 선택된 0.1%이다. 모델은 디코딩 과정동안 부분 번역에 점수를 메기기 위해 사용되었다. 이 디코딩 과정은 일반적으로 n-best list rescoring보다는 BLEU 점수에서 더 높은 점수를 얻는다.
디코더에서 CSLM 사용의 계산 복잡도를 해결하기 위해 디코더에서 수행되는 stack search동안 n-gram을 합치는데 버퍼가 사용된다. 버퍼가 가득 찼을 때 또는 스택이 축소될때 n-gram은 CSLM에 의해 점수가 메겨진다. 이는 Theano를 사용한 GPU에서 빠른 행렬 곱을 수행할 수 있게 한다.
4.2 Quantitative Analysis
우리는 다음과 같은 조합을 시도했다.
- Baseline configuration
- Baseline + RNN
- Baseline + CSLM + RNN
- Baseline + CSLM + RNN + Word penalty
결과는 Table 1에 있다. 예상한대로 신경망에 의해 계산된 feature를 추가하는 것은 baseline 성능보다 지속적으로 향상된다.
가장 좋은 퍼포먼스는 CSLM과 RNN 인코더-디코더로부터 얻은 구문 점수를 함께 사용했을때 얻어냈다. 이는 CSLM과 RNN 인코더-디코더의 기여가 크게 상관이 있지 않고 각 방법을 독립적으로 향상했을 때 더 나은 결과를 기대할 수 있을것을 암시한다. 게다가 우리는 신경망에 알려지지 않은 단어 수에 페널티를 적용했다(short list에 있지 않은 단어들). 우리는 식(9)의 로그 선형 모델에 추가기능으로 알 수 없는 단어의 수를 추가함으로써 이를 수행한다. 하지만 이 경우에 테스트셋에서는 더 나은 성능을 달성할 수 없지만 검증용 셋에서는 달성할 수 있다.
4.3 Qualitative Analysis
성능 향상이 어디로부터 오는지 이해하기 위해 번역 모델의 해당 p(f | e)에 대해 RNN 인코더-디코더에서 계산한 구문 쌍 점수들을 분석한다. 현재 번역 모델이 말뭉치의 구문 쌍들의 통계량에만 의존하기 때문에 우리는 자주 등장하는 구문들에 대해 모델의 점수가 더 좋게 평가될 것을 기대할 수 있지만 자주 등장하지 않는 구문은 나쁘게 평가될 것이라고 예상한다. 또한 3.1절에서 언급한것 처럼 빈도 정보 없이 훈련된 RNN 인코더-디코더가 말뭉치에서의 발생 통계량보다는 언어적 규칙성을 기반으로 구문쌍의 점수를 매길것으로 예상한다.
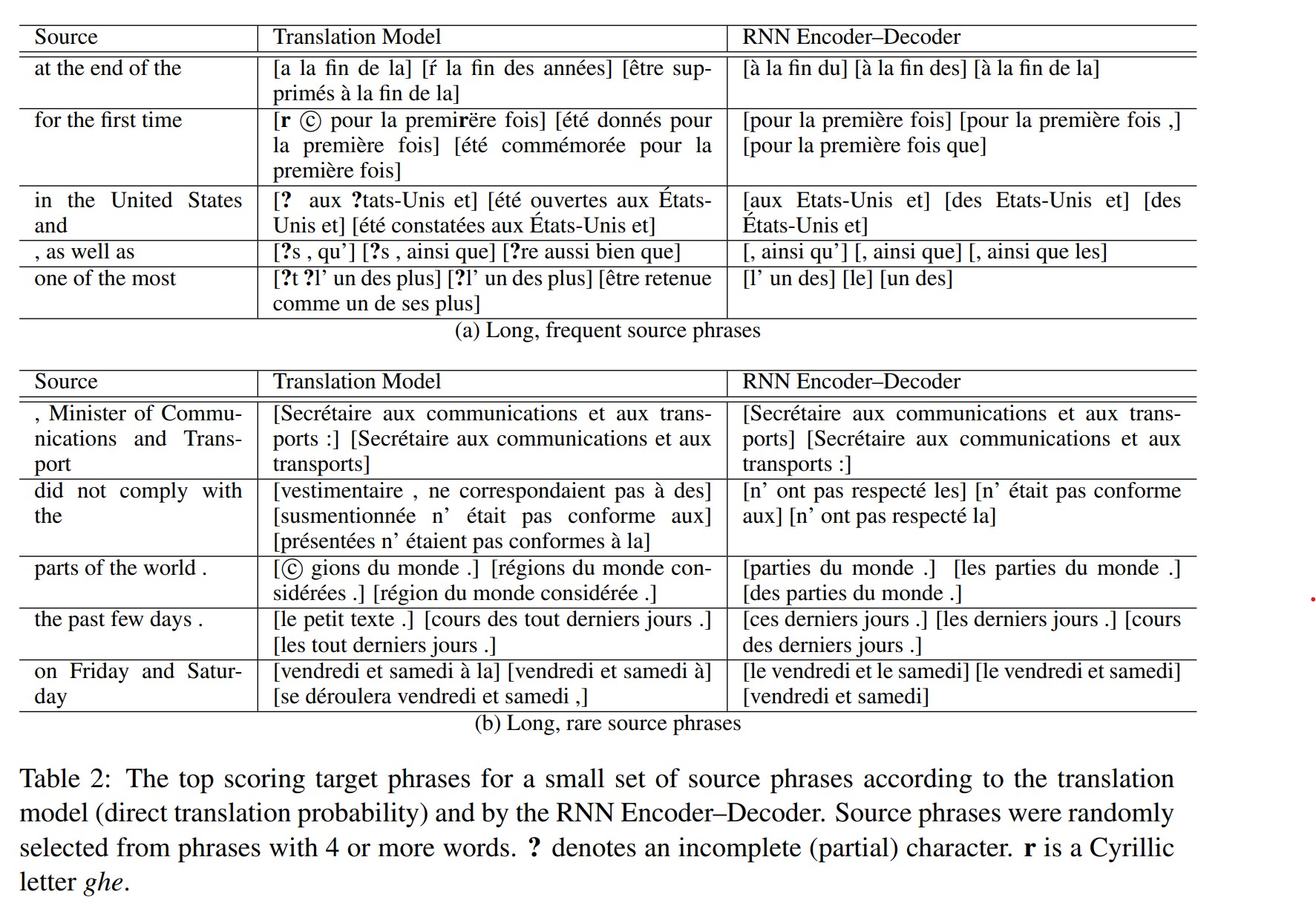
우리는 소스 구문이 길고(한 구문에 3개 이상의 단어) 자주 발생하는 구문의 쌍에 집중한다.

각 소스 구문에서 우리는 번역 확률 p(f|e) 또는 RNN 인코더 디코더에 의해 점수가 높게 매겨진 타겟 구문을 본다. 유사하게 우리는 말뭉치에서 소스 구문이 길지만 드문 구문쌍들로 같은 과정을 수행한다.
표 2는 번역 모델이나 RNN 인코더-디코더가 선호하는 소스 구문당 타겟 구문 상위 3개 목록을 작성한다. 소스 구문들은 4개 또는 5개 단어를 가지는 긴 구문중에 선택된 것이다.
대부분의 경우에서 인코더-디코더에 의한 타겟 구문들의 선택은 실제 또는 직역에 가깝다. 우리는 RNN 인코더-디코더는 일반적으로 짧은 구문들을 선호하는 것을 알 수 있다.
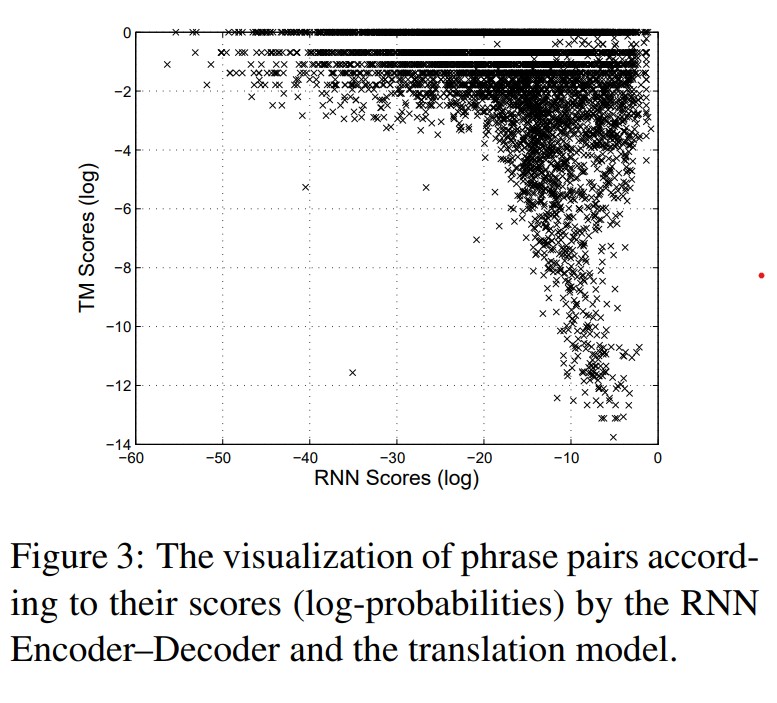
흥미롭게도 많은 구문 쌍들은 번역 모델 그리고 RNN 인코더-디코더에 의해 유사하게 점수가 매겨졌지만 매우 다르게 점수가 매겨진 많은 구문쌍들이 있다(그림3). 이는 고유한 구문 쌍 세트에 대해 RNN 인코더-디코더를 훈련하는 제안된 접근법에서 발생할 수 있고 앞에서 설명한 것처럼 RNN 인코더-디코더가 말뭉치에서 구문쌍의 빈도를 단순히 학습하는 것을 방해한다.
게다가 표3에서 표2의 각 소스 구문에 대해 RNN 인코더 디코더에서 생성된 샘플을 보여준다. 각 소스 구문에서 50개의 샘플을 생성했고 그들의 점수에 따른 상위 5개의 구문을 본다. RNN 인코더-디코더가 실제 구문 테이블 보지 않고도 잘 형성된 타겟 구문을 제안할 수 있음을 알 수 있다. 중요한것은 생성된 구문들은 구문 테이블의 타겟 구문들과 완전히 겹치지 않는다. 이것은 미래에 구문 테이블의 전체 또는 일부를 제안된 RNN 인코더-디코더로 대체할 가능성을 추가로 조사하도록 권장한다.
4.4 Word and Phrase Representation
제안된 RNN 인코더-디코더는 기계번역 업무를 위해 특별히 디자인되지 않았기 때문에 훈련된 모델의 특징을 간단히 살표분다.
신경망을 사용한 연속 공간 언어 모델들이 유의한 임베딩을 학습할 수 있는 것은 오래전부터 알려져왔다. 제안된 RNN 인코더-디코더는 일련의 단어를 연속적인 공간 벡터로 투영하고 다시 매핑하므로 제안된 모델에서도 유사한 속성을 볼 수 있을 것으로 예상한다.
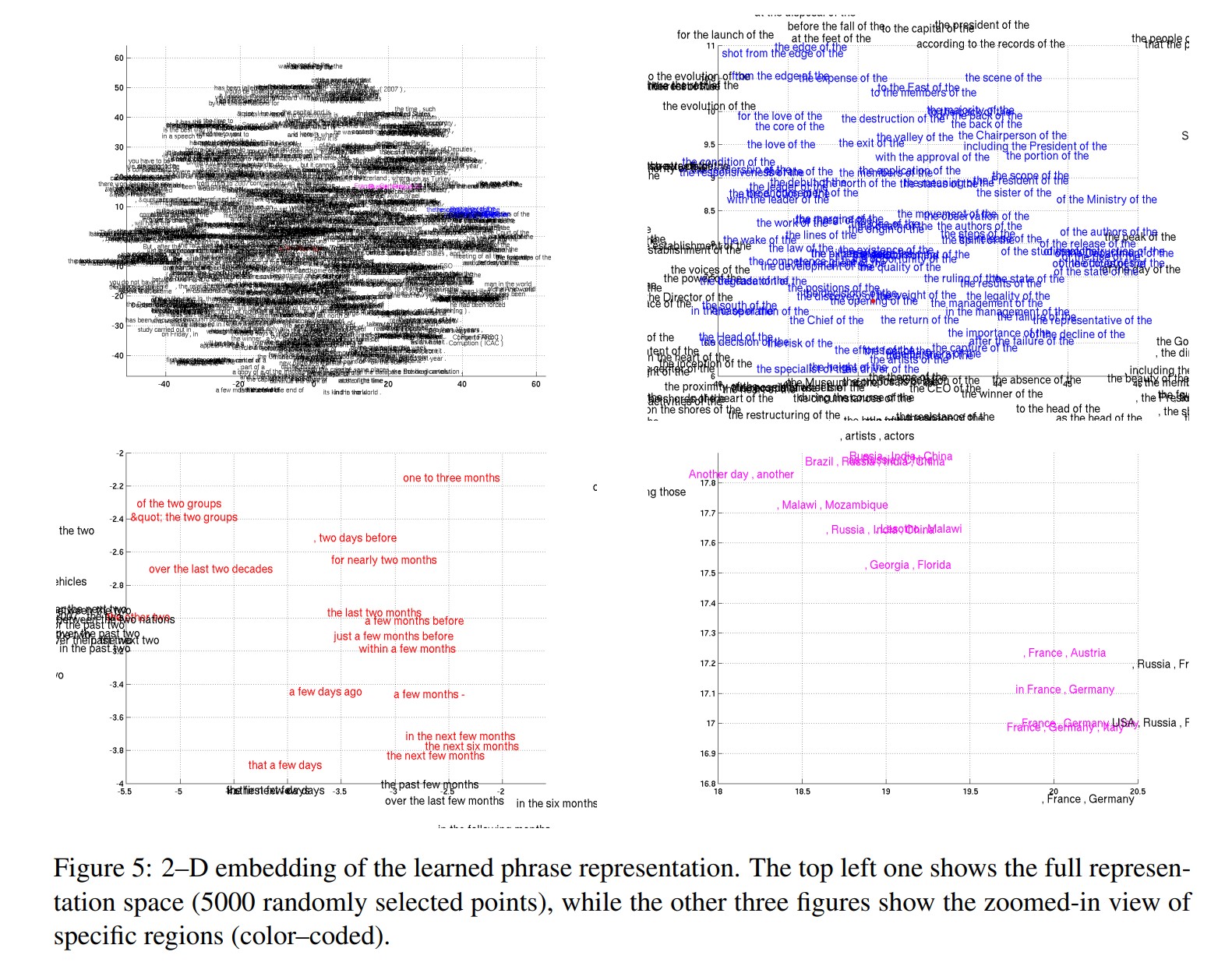
그림4의 왼쪽 그림은 RNN 인코더-디코더에 의해 학습된 단어 임베딩 행렬을 사용한 단어의 2D 임베딩을 보여준다. 사영은 최근에 제안된 Barnes-Hut-SNE(van der Maaten, 2013)에 의해 끝났다. 의미적으로 유사한 단어들이 서로 군집을 이루는 것을 명확히 볼 수 있다(그림4의 줌인된 플롯을 봐라).
제안된 RNN 인코더-디코더는 구문의 연속공간 표현을 생성한다. 이 경우에 표현(그림1의 c)는 1,000차원 벡터이다. 단어 표현과 유사하게 그림5에서 Barnes-Hut-SNE를 사용한 4개 이상의 단어로 구성된 구문의 표현을 시각화했다.
시각화로부터 RNN 인코더-디코더는 구문의 의미적, 구문적 구조를 모두 포착하는 것이 명확해졌다. 예를 들어 왼쪽 아래 플롯에서 대부분의 구문은 시간의 duration에 관한 것인 반면에 구문적으로 유사한 구문들은 함께 모여있다. 오른쪽 아래 플롯은 의미적으로 유사한(도시, 지역) 구문의 군집을 보여준다. 한편 오른쪽 위 플롯은 구문적으로 유사한 구문들을 보여준다.
5 Conclusion
이 논문에서 우리는 RNN 인코더-디코더라고 불리는 새로운 신경망 아키텍처를 제안했다. 이 RNN 인코더-디코더는 임의 길이의 시퀀스에서 다른 시퀀스로, 가능하면 임의 길이의 다른 셋에서 매핑을 학습할 수 있다. 제안된 RNN 인코더-디코더는 시퀀스의 쌍에 점수를 매길 수 있고 주어진 소스 시퀀스로 타겟 시퀀스를 생성할 수 있다. 새로운 아키텍처와 더불어 시퀀스를 읽거나 생성하는 동안 각 은닉 유닛이 얼마나 기억하고 잊어버릴지 자유자재로 통제하는 reset, update 게이트를 포함하는 새로운 은닉 유닛을 제안했다.
구문 테이블에서 각 구문쌍의 점수를 매기기 위해 RNN 인코더-디코더를 사용한 SMT 작업으로 제안된 모델을 평가했다. 정성적으로 새로운 모델이 구문 쌍들의 언어적 규칙성과 RNN 인코더-디코더가 잘 형성된 타겟 구문을 내놓을 수 있다는 것을 보일 수 있었다.
RNN 인코더-디코더의 점수들은 BLEU 점수 관점에서 전체적인 번역 성능을 향상시키는 것으로 나타났다. 또한 RNN 인코더-디코더의 기여는 SMT 시스템에서 신경망을 사용하는 기존 접근법과 직교한므로 예를 들어 RNN 인코더-디코더와 신경망 언어 모델을 함께 사용함으로써 성능을 향상시킬 수 있다.
훈련된 모델의 정성적 분석은 복합적인 레벨에서, 즉, 단어 레벨뿐만 아니라 구문 레벨에서 언어적 규칙성을 포찰한다는 사실을 보여준다. 이는 제안된 RNN 인코더-디코더로부터 이득이 되는 자연어 관련 적용이 더 있을 수 있음을 암시한다.
제안된 아키텍처는 추가적인 향상과 분석에 대해 큰 잠재력을 가지고 있다. 여기서 조사하지 않은 한가지 접근법은 RNN 인코더-디코더가 타겟 구문들을 제시할 수 있게 함으로써 구문 테이블의 전체 또는 일부를 대체하는 것이다. 또한 제안된 모델은 문자 언어에만 제한되지 않고 speech transcription(음성 받아쓰기)와 같은 곳에 적용하는 아주 중요한 연구가 될 것이다.
댓글남기기