1/20
프로젝트 주제 선정
현대사회에서 많은 사람들이 자신이 탈모인지 확신하지 못해 병원을 찾지 않는 경우가 많아, 치료의 골든 타임을 놓치는 일이 빈번하게 발생한다.
∴ 탈모 및 두피질환에 대한 확실한 정보 제공
-> 사용자가 자신의 상태를 정확히 인지 & 적절한 조치를 취하게 돕고자 함
서비스 형태
- 사용자의 두피 사진 업로드
- 웹 서비스에서 사용자의 생활습관(펌횟수, 염색 횟수, 샴푸 횟수 등) 입력
- 사용자의 두피 상태 분석
- 두피 상태 분석 결과 제공
- 두피 분석 결과와 생활습관을 바탕으로 개인 맞춤형 솔루션 제공
- 추가적으로 두피 질환 관련 정보를 공유할 수 있는 커뮤니티 서비스 제공
데이터 설명
-
이미지 종류
질환 종류 : 미세 각질, 피지 과도, 모낭사이홍반, 모낭홍반농포, 비듬, 탈모
심각도 : 양호(0), 경증(1), 중등도(2), 중증(3)
-
이미지 수집
AI허브 공개 데이터셋 활용
크롤링으로 추가 이미지 수집
-
탈모 단계별 이미지

-
추가 두피 질환 이미지

와이어프레임
-
메인페이지
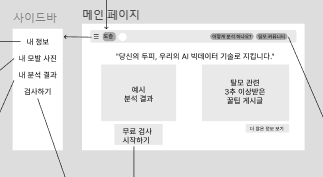
-
사이드바
-
내 정보

-
내 모발 사진

-
내 분석결과

-
분석 결과
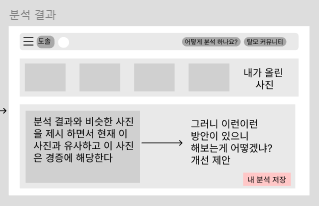
-
검사하기
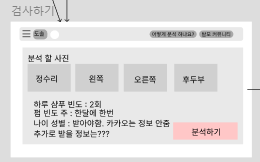
-
-
-
로그인 및 회원가입


-
게시판 커뮤니티

-
게시글 상세보기

-
모델 선정 및 설명
기존모델 튜닝
AIhub에 데이터와 함께 올라와있는 모델을 튜닝하여 성능을 높이는 방법을 찾는다. 기존 모델은 EfficientNet-b7을 이용했다. 기존의 측정값 점수는 다음과 같다.
| 번호 | 측정항목 | AI TASK | 학습모델 | 지표명 | 기준값 점수 | 측정값 점수 |
|---|---|---|---|---|---|---|
| 1 | 미세갈질 분류 모델 | Image Classification | CNN | Accuracy | 85 % | 91.3 % |
| 2 | 피지과다 분류 모델 | Image Classification | CNN | Accuracy | 85 % | 90.5 % |
| 3 | 모낭사이홍반 분류 모델 | Image Classification | CNN | Accuracy | 85 % | 89.6 % |
| 4 | 모낭홍반/농포 분류 모델 | Image Classification | CNN | Accuracy | 85 % | 87.3 % |
| 5 | 비듬 분류 모델 | Image Classification | CNN | Accuracy | 85 % | 95.2 % |
| 6 | 탈모 분류 모델 | Image Classification | CNN | Accuracy | 85 % | 89 % |
- 하이퍼 파라미터 튜닝
- 하이퍼 파라미터 최적화 : 학습률, 배치 크기 등 세부 설정 조정
- 손실 함수 및 옵티마이저 변경
- CrossEntropyLoss 외에도 다른 손실함수를 적용하여 성능 개선
- AdamW, SGD 등 다양한 옵티마이저로 수정
새로운 모델 설계
-
최신 모델 사용
ResNet, DenseNet, Vision Transformer 등 최신 모델 검토 후 실험
-
Ensemble
EfficientNet과 새로운 모델을 결합
-
CustomCNN 설계
탈모 이미지 분류에 특화된 맞춤형 CNN 개발
학습결과
기존 모델 변경
문서에 포함된 모델에서 약간의 수정을 했다.
- EarlyStopping 추가
- 배치 크기 2로 수정
- b7 -> b0 모델로 변경
학습 결과(이미지-EfficientNet)
-
1.png
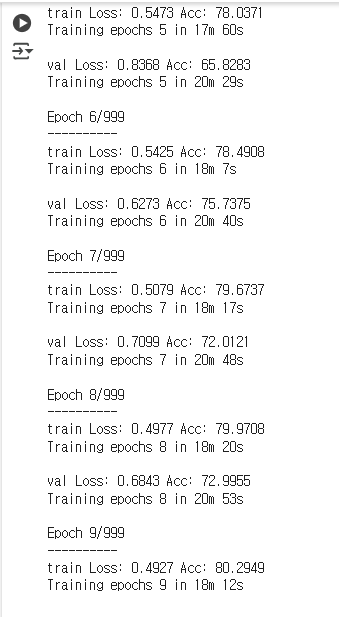
가장 처음 돌린 모델은, AI hub에 데이터를 올린 업체에서 만든 모델을 그대로 돌리려 했지만, 리소스의 이슈로 인해 코드 자체가 돌아가지 않았다. 그래서 배치 크기를 줄이고 모델을 efficientnet-b7에서 더 경량화된 모델인 b0(파라미터의 개수는 약 10배, 연산량은 약 100배 차이가 난다)모델을 돌렸다. AI hub 문서에서 정확도 89%였지만, 모델을 돌릴 수 있도록 수정했더니 80%로 떨어졌다.
-
2.png
변경사항
-
hyper_param_batch = 2에서 4로 변경
-
이미지 증강 코드 추가
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1), transforms.RandomResizedCrop(600, scale=(0.8, 1.0)), transforms.GaussianBlur(5, sigma=(0.1, 2.0)) -
학습률 수정
1e-4에서 1e-3으로 수정
-
옵티마이저 변경
Adam => AdamW로 수정
Adam : Momentum + RMSProp
AdamW : Adam 개선 버전으로, L2정규화를 올바르게 적용하도록 개선된 알고리즘
-
스케줄러 변경
StepLR => ReduceLROnPlateau로 수정
성능 개선이 정체될 때 학습률을 줄여 과적합 방지
exp_lr_scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer_ft, mode='max', factor=0.5, patience=5, verbose=True)파라미터 설명
optimizer_ft : 옵티마이저 인스턴스, 학습률을 동적으로 조정한다.
mode : 모니터링하는 지표가 최대인지, 최소인지 지정
factor : 성능 향상이 없을 때, 학습률을 factor 배 만큼 줄인다.
patience : 지정한 횟수동안 개선되지 않으면 학습률 감소
verbose : 학습률이 감소할 때 메시지 출력
-
이미지 해상도 조정
(600, 600)에서 (800, 800)으로 수정
-
텍스트 생성 모델
우리가 원하는 최종 모델은 사용자의 이미지를 입력받았을 때, 사용자의 두피에 있는 질환(미세각질, 피지과다, 모낭사이홍반, 모낭홍반/농포, 비듬, 탈모)의 심각도(양호 : 0 ~ 중증 : 3)를 예측해준 뒤, 사용자에게 메타 데이터(염색주기, 펌 주기, 샴푸사용 빈도 등)를 입력받아 두가지 팩터를 결합하여 사용자 맞춤 솔루션을 추천해주는 모델이다.
이를 위해서 생각한 방법은 이미지를 입력받으면 6가지 질병의 심각도를 예측해주는 A모델,
질병의 심각도와 메타데이터를 입력받아 맞춤 솔루션을 제공해주는 텍스트 생성 모델 B 모델 두가지로 파이프라인을 분리해서 만드는 것이다.
다음 그림과 같다.

모델 선정
텍스트 생성을 위한 적절한 모델로 다음과 같은 후보를 검토하였다.
-
GPT(Generative Pre-trained Transformer)
OpenAI에서 개발한 자연어 처리 모델로, 방대한 사전 학습 데이터를 바탕으로 다양한 텍스트 생성 능력을 보유.
GPT-3,GPT-4모델이 있지만 상업적 라이선스 문제와 비용이 존재. -
LLaMA (Large Language Model Meta AI)
Meta에서 개발한 대규모 언어 모델로 오픈소스로 제공되며, 성능과 비용의 균형을 유지하기에 적합.
LLaMA 2및KoAlpaca-LLAMA등 한국어 특화 버전도 존재. -
KoAlpaca
한국어에 특화된 LLaMA 모델로, 한국어 자연어 생성 및 이해가 뛰어나며, Hugging Face에서 사용 가능. 상대적으로 경량화된 모델을 제공하여 개인화 솔루션 구축에 적합.
모델 선정 과정
-
LLaMA 모델 테스트
meta-llama/Llama-2-7b-chat-hf모델을 Hugging Face에서 로드하려 했으나, 접근 권한 문제로 모델 다운로드 및 실행 실패.- 해결을 위해 Hugging Face 계정 로그인 및 API 토큰을 활용했으나, 모델 실행 시 메모리 문제 발생
-
KoAlpaca 모델 테스트
-
beomi/koalpaca-llama-1-7b모델을 로컬 환경에 다운로드 후 실행 시도.- SentencePiece 및 BitsAndBytes 패키지 설치 및 모델 양자화를 시도했으나, 8-bit/4-bit 양자화 관련 라이브러리(
bitsandbytes) 충돌 발생.- 모델 메모리 문제 해결을 위해 4-bit 양자화를 적용했으나, 여전히 실행 불가능. => 하드웨어 문제로, Colab A100에서 실행을 할 수 있었다.
-
추가적인 문제 해결 과정
- Hugging Face CLI를 통한 로그인(
huggingface-cli login) 수행 후 API 토큰 적용.- GPU 사양 확인.
-최신 버전의 PyTorch, Hugging Face Transformers 패키지를 설치 및 업데이트 수행.
데이터 전처리 과정
텍스트 생성 모델의 입력 데이터를 최적화하기 위해 다음과 같은 전처리 작업을 수행하였다.
-
데이터 정제
-
불필요한 특수 문자 및 공백 제거
- 중복된 응답을 제거 및 정렬하여 일관된 데이터 제공
- 한글 및 영어, 숫자만 남기고 불필요한 문자를 필터링하는 정규 표현식 적용
-
데이터 포맷 표준화
-
사용자 연령(예: “30대” → “30-“) 변환
- 텍스트 형식 가다듬기 및 특수 기호 조정
-
데이터 예제 생성
formatted_text = ( f"{meta_data['age']} {meta_data['gender']} 사용자, 위치: {meta_data['location']},\n" f"샴푸 사용 빈도: {meta_data['answers1']}, 펌 주기: {meta_data['answers2']}, " f"염색 주기: {meta_data['answers3']}, 현재 모발 상태: {meta_data['answers4']},\n" f"사용 제품: {meta_data['answers5']}, 두피 케어 희망: {meta_data['answers6']}, " f"구매 고려 사항: {meta_data['answers7']}.\n" f"두피 분석 결과: value_1={label_data['value_1']}, value_2={label_data['value_2']}, " f"value_3={label_data['value_3']}, value_4={label_data['value_4']}, value_5={label_data['value_5']}, " f"value_6={label_data['value_6']}.\n" f"사용자 맞춤 샴푸 및 생활습관 솔루션: " )
학습 및 텍스트 출력
학습
from peft import get_peft_model, LoraConfig, TaskType
lora_config = LoraConfig(
task_type=TaskType.CAUSAL_LM, # 언어 모델 학습
inference_mode=False, # 학습 모드
r=8, # 랭크
lora_alpha=32, # LoRA scaling factor
lora_dropout=0.1 # Dropout
)
# LoRA 적용 (모델 로드 후 바로 적용)
model = get_peft_model(base_model, lora_config)
PEFT의 일종인 LoRA를 적용해 모델을 학습시켰다.
출력
추천 솔루션이 출력됐지만 이렇게 이상하게 나왔다.
추천 솔루션: 샴푸 사용 제품 중 예를 들어 샴푸 샴푸 케어 희망을 예약하세요. 샴푸 케어 희망을 예약하면 샴푸 샴푸를 구매하고 샴푸 샴푸를 사용할 수 있습니다. 샴푸 샴푸를 사용하면 샴푸 샴푸를 사용하고 샴푸 샴푸를 사용할 수 있습니다. 샴푸 샴푸를 사용하면 샴푸 샴푸를 사용하고 샴푸 샴푸를 사
문제 분석
-
훈련 데이터 부족
훈련데이터를 처음에 50개만 사용해서 훈련 데이터 부족
-
generate() 함수 개선
- 기존의 함수
output = fine_tuned_model.generate(input_tokens["input_ids"], max_length=512)- 옵션 추가
output = fine_tuned_model.generate( input_tokens["input_ids"], max_length=256, # 너무 긴 문장 방지 num_return_sequences=1, # 한 개의 결과만 생성 temperature=0.7, # 낮추면 더 일관적인 문장 생성 top_p=0.9, # 확률 분포 기반 샘플링 repetition_penalty=1.5, # 단어 반복 방지 do_sample=True # 랜덤 샘플링 활성화 ) -
LoRA 훈련 횟수 증가
num_train_epochs를 3번만 돌렸는데, 훈련 횟수가 부족해 보인다.
-
규칙 기반 로직 추가
비지도학습만으로는 모델 성능이 부족하다고 판단되었다. 하지만 모든 데이터에 솔루션을 라벨링 하기에는 시간적인 문제와 무엇보다 전문가가 사진과 메타데이터로 판단해야 하는 영역이라고 생각해, 규칙 기반 로직을 추가하였다.
def generate_solution(label_data): # 두피 상태에 따른 솔루션 결정 if label_data['value_1'] == 1: return "지성 두피용 샴푸와 주 1회 두피 스케일링을 권장합니다." elif label_data['value_2'] == 1: return "건성 두피용 샴푸와 보습 트리트먼트를 추천합니다." elif label_data['value_3'] == 1: return "민감성 두피용 저자극 샴푸와 천연 오일 사용을 권장합니다." else: return "일반 두피용 샴푸와 주기적인 두피 마사지로 관리하세요."우선 규칙 기반 로직을 끼워넣어 결과가 어떻게 나오나 확인하려 했지만
OutOfMemoryError: CUDA out of memory. Tried to allocate 252.00 MiB. GPU 0 has a total capacity of 39.56 GiB of which 896.00 KiB is free. Process 5414 has 39.55 GiB memory in use. Of the allocated memory 38.91 GiB is allocated by PyTorch, and 130.74 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. See documentation for Memory ManagementOutOfMemory 에러가 발생했고,
bnb_config = BitsAndBytesConfig( load_in_8bit=True, llm_int8_enable_fp32_cpu_offload=True # 8-bit 양자화 시 CPU 오프로드 활성화 )bnb 설정을 8비트 양자화로 수정하니까 실행이 됐다.
댓글남기기