3/11 HuggingFace-NLP 1. Transformer Models
카카오톡 오픈채팅으로 들어간 NLP 스터디에서 HuggingFace NLP Course(NLP Course 번역ver.)로 스터디를 진행하기로 했다. 중요한 이론적 내용을 포스팅하고 코드 부분은 깃허브로 따로 첨부하려고 한다. .
NLP
- NLP 작업의 종류
- 문장 분류 : 리뷰의 감정 분석, 스팸메일 감지, 문장 문법 검사, 두 문장의 논리적 연관성 파악
- 문장의 단어 분류 : 문법적 요소 식별(명사, 동사, 형용사 등), 개체 인식(사람, 위치, 기관)
- 텍스트 생성 : 자동 생성 텍스트로 프롬프트 완성하기, 마스킹된 텍스트 빈칸 채우기
- 텍스트로부터 정답 추출 : 주어진 질문과 문맥에서 제공된 정보를 기반으로 질문의 답변 추출하기
- 입력 텍스트로부터 새로운 문장 생성 : 문장 번역, 텍스트 요약
Pipeline
pipeline 라이브러리로 수행가능한 작업은 다음과 같다.
- feature-extraction : 특징 추출
- fill-mask : 빈칸 채우기
- ner : 개체명 인식
- question-answering : 질의응답
- sentiment-analysis : 감정분석
- summarization : 요약
- text-generation : 텍스트 생성
- translation : 번역
- zero-shot-classification : 제로샷 분류
트랜스포머 기반 모델
| Model | Examples | Tasks |
|---|---|---|
| 인코더 | ALBERT, BERT, DistilBert, ELECTRA, RoBERTa | 문장 분류, 개체명 인식, 추출 질의 응답 |
| 디코더 | CTRL, GPT, GPT-2, Transformer XL | 텍스트 생성 |
| 인코더-디코더 | BART, T5, Marian, mBART | 요약, 번역, 생성 질의응답 |
트랜스포머의 특성
-
언어모델
- self-supervised learning : 목적함수를 모델 스스로 계산하여 학습. 사람이 레이블링을 할 필요가 없다.
- 전이학습 : 1. 과정에서 사전학습된 모델을 fine-tuning을 거쳐 모델을 완성한다.
-
대규모 모델
트랜스포머는 대규모 모델로 사전학습된 모델을 공유하지 않고 각 조직이 개별적으로 모델을 사전학습한다면 환경적인 문제(온실가스 배출)가 발생할 것이다.
-
전이학습
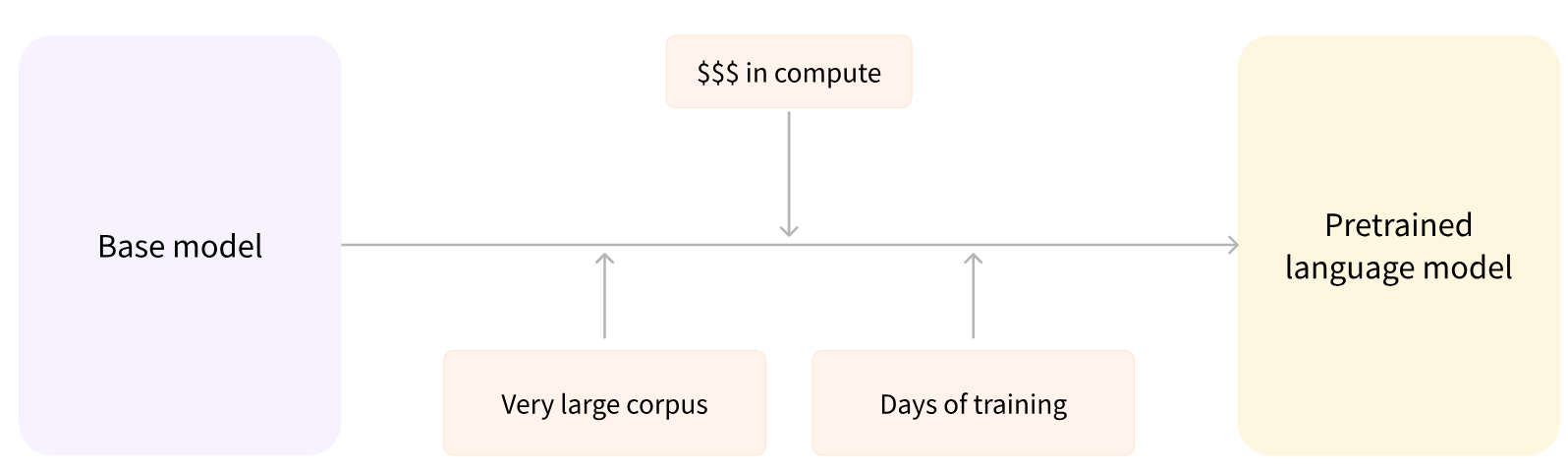
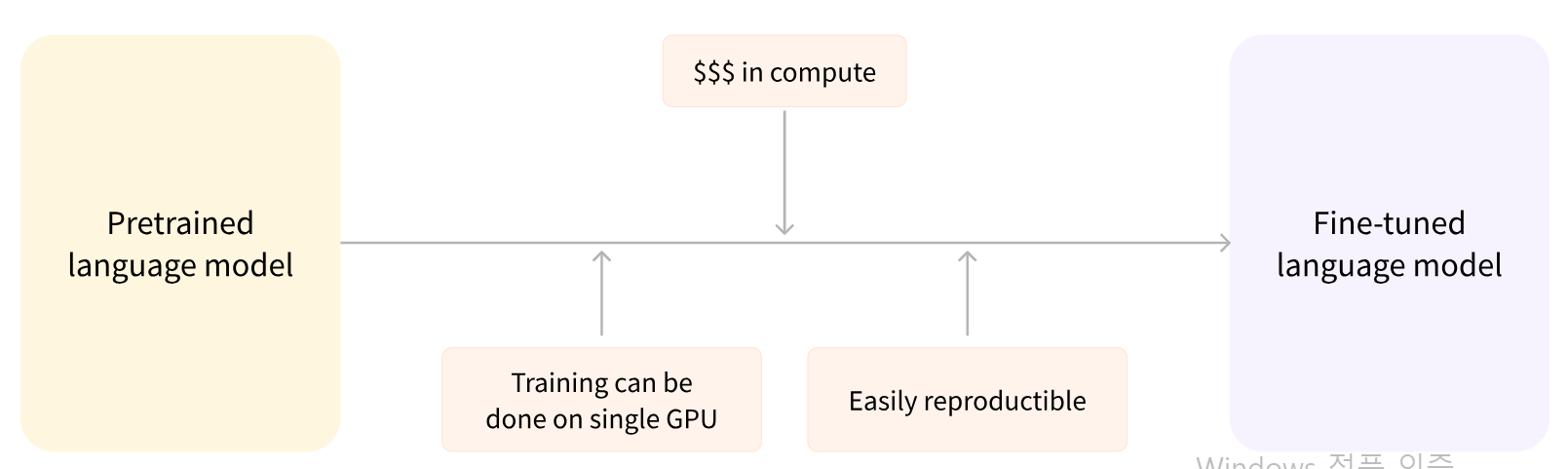
아키텍처 vs 체크포인트
- 아키텍처 : 모델의 레이어, 연산 등을 의미함(뼈대)
- 체크포인트 : 아키텍처에서 로드될 가중치 값(bert-base-cased : 사전학습된 가중치 값들)
인코더 vs 디코더
- 인코더 : 입력에 대한 이해를 요구하는 작업에 적합(문장 분류, 개체명 인식, 단어분류)
- 디코더 : 출력 생성에 적합(텍스트 생성)
- 인코더-디코더(or seq2seq) : 번역, 요약과 같이 입력에 대한 이해와 출력 모두를 수행해야 하는 작업에 적합함
댓글남기기